fursuit 吧: Archive and Time Machine
This article was originally published on the “fursuit 吧: Archive and Time Machine” project homepage.
Note: “吧” (ba) refers to a Baidu Tieba community, similar in concept to a subreddit. While often translated as “bar” or “forum”, the original term is preserved here.
Hey, I’m catme0w, the author of “fursuit 吧: Archive and Time Machine”. First of all, thank you for making it here!
“Archive and Time Machine” is one of my biggest projects. It’s both an attempt to trace the roots of furry culture (though mainly fursuit) in China, and a gift to myself. I’ve always desperately wanted to restore this data that I thought was permanently lost. Now I finally have it, and the creator of this gift is none other than myself. I can say that when I saw it come to life, I was happier than anyone else.
That said, since you’ve made it here, you must want to understand the full story of this project, or maybe you have questions for me. Get ready, let’s travel back to the summer of 2012…
Origin
In June 2012, through a long-forgotten opportunity, I stumbled upon the Baidu Tieba fursuit 吧.
What greeted me were mostly collections of fursuit images gathered from various places, usually photo sets from individual fursuiters. There were also many videos imported from YouTube, like EZ Wolf’s “Gangnam Style” or Keenora’s fursuit bungee jumping.
I can’t describe how I felt when I first saw fursuits. It was something… I had never encountered before. Very magical, very subtle.
Very captivating.
I thought, then let’s stay.
I was interested in this unprecedented new thing, but at the same time carefully maintained a sense of distance. I didn’t immediately press the join button, just came back every few days to check the latest posts.
The trending content in the 吧 changed constantly. With my infrequent visits, almost every time I came, the homepage had changed quite a bit.
One time, several posts near the top were “3D images”, which were actually just the same image placed on both left and right sides, meant to be viewed cross-eyed for a 3D effect.
But this was still 2012, and China’s first full suit wouldn’t appear until 2013.
I didn’t know about furry back then, and didn’t think of it in terms of animals. In fact, I had been immersed in the fursuit world for quite a while before I realized the existence of furry as the “upstream”.
Time came to 2015, when China held its first fur con in history, “神州萌兽祭”.
By this time, we already had several decent fursuits, mostly self-made. We were still far from leaving the pastoral period.
Unfortunately, that summer I was too busy dealing with my Minecraft server partner running away with money, and completely missed this memorable major event. I have very few impressions of the first fur con in 2015.
Looking back, this was really picking up sesame seeds while losing watermelons. Minecraft never gave me happiness beyond the game content itself. Running a server was purely asking for trouble. Why not put energy into things that can make me relax?
Another year passed, now it’s 2016.
That midsummer will forever be the most classic fur con in my heart. It was called “兽夏祭”.
At least in the fursuit world, that summer was an unprecedented carnival. We already had quite a few formidable suit makers, and more fursuits than you could count on all your hands and feet combined. The joyful atmosphere of the fur con even spread to the human world, bringing many new people into this extremely niche community at the time. Our numbers could now be counted in thousands.
And the boom of “fursuit livestreaming” also started from that time.
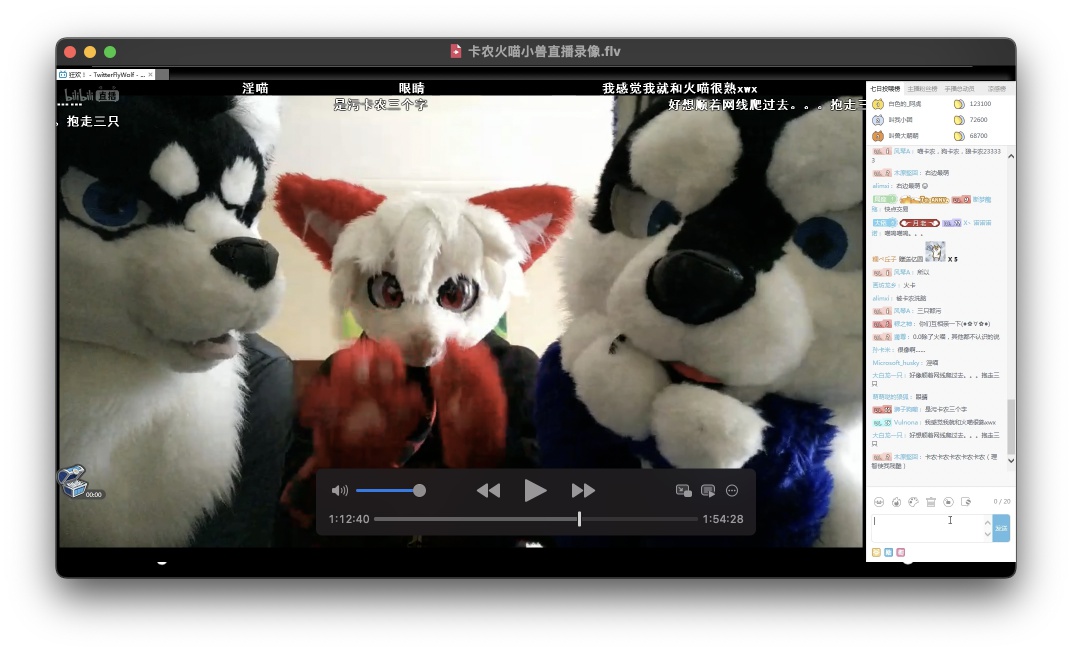
卡农’s name is now 流银, 小兽’s name is now 艾尔, and 火喵 is still that same 火喵.
After an unforgettable summer, we moved toward 2017.
Unfortunately, the 2017 兽夏祭 was unsatisfactory, could be described as having mixed reviews.
But beyond that, a more serious crisis was brewing…
The history as we knew it was about to meet its end.
Doomsday
As you’ve already seen on the archive homepage:
On June 19, 2017, the top moderator “混血狼狗” had their position revoked by Baidu.
On June 20, 2017, user “布偶新世界” claimed responsibility for the incident of the original moderators’ unexpected removal.
On June 23, 2017, the fursuit 吧 began to suffer from spamming attacks.
…
From June 2017 to July 2018, the fursuit 吧 intermittently suffered spamming attacks, spanning over a year.
During this period, moderators changed hands multiple times, and nearly all quality posts from the 吧’s early days were deleted.
The Library of Alexandria symbolizing China’s fursuit culture was burned down in an instant. Our history was gone.
In 2018, after a year of warfare, everything seemed to have settled. The original moderation team was completely purged, replaced by “艾布” and “糊兔”, along with many of their own subordinates.
They not only purged the moderation team but also destroyed their posts along with a large number of quality posts from others.
The development history of fursuit in China was severed at its roots in an instant.
The ending of the story is that after they completely took over the 吧, all the spamming bots disappeared overnight.
I later learned that in the three years after they succeeded, the backend operation records totaled less than 50 entries. More than 30 of those were just cleaning up traces of previous spam.
The 吧 stagnated. This state of completely halted development lasted three years, like what’s described in novels as “the bright Middle Ages”.
I don’t know why they did this. I really want to question them: what good does this do you? If you wanted to steal the 吧, fine, have it, but why destroy civilization, destroy history?
Did you go through all that trouble just to destroy it?
“艾布”, “糊兔”, “软毛”, “LL”, “大召唤之门” - all these people’s names and identities are tangled together into a mess. I don’t even know who I should be looking for.
I don’t know who they are, but they are the people I hate most.
Part I: Dawn
One afternoon in November 2021, I had a dream.
It was a very, very large theater, lights off, with only me standing under a spotlight.
This was a fur con, but at this moment it looked exactly like an Apple product launch event. And I was standing where Tim Cook should appear.
Facing the sea of people before me, I held up a disc. This was what I was launching.
This disc contained the fully restored copy of the fursuit 吧, including all the data destroyed by 艾布 and the others.
I had restored the data, it was in this disc, and now I was going to show it to the world.
Go to hell, 艾布. You didn’t succeed.
…
I woke up.
I woke up…
…
If only what was in the dream were real. How wonderful that would be.
How wonderful…
Maybe, let’s go take a look. See what it’s like there now.
There were no moderators there anymore. They had left.
And at this time, someone was trying to apply to be a moderator again. Her name was “冰清”, a name I had never seen before.
I had deleted my own Baidu account in the year when 艾布 and the others descended. I couldn’t take action myself. If 冰清 could successfully become a moderator, asking for her help would be the only viable path.
A few days later, 冰清 became the new moderator as expected.
Well then, it’s my turn to take the stage of history.
I’m going to rewrite history.
Part II: Creatio ex Nihilo
There’s hope now, there’s hope.
I began brainstorming, thinking about what I could do.
Should I directly restore it, or do something bigger, like make a cyber ruins park or something?
But before that, I needed to figure out what exactly happened back then. I had to find her, have her make me a moderator. Only by personally seeing the backend history records could I determine my next moves.
冰清 quickly agreed. I’m very grateful to her for giving such great trust to a stranger.
But when I actually saw the backend, I was still stunned.
Before this, I had already speculated several possible scenarios, but what actually happened still completely exceeded my imagination.
“play月光如水k” - who is this? All the destruction was done by this account. This account deleted almost all the quality posts.
And I had no idea such a person ever existed. I had never seen this person in the 吧, whether in posts or on the moderation list.
Worse yet, this account had already been deleted, and I couldn’t find out anything about their past.
Along with “play月光如水k”, there were several others who deleted their accounts and fled, including “飛翔之龍” and “大召唤之门”. Even more peculiar, the account that was once “糊兔” had now become 艾布’s name. I couldn’t think of any reasonable explanation for this.
Forget it. Don’t waste time reviewing the actions of these absurd people. Now only one thing matters: data integrity.
I contacted several of my technically skilled friends. After another round of brainstorming (though most of the time I was just talking to thin air) and several plan overhauls, I finally clarified what I wanted to make:
A “time machine” that could trace back to any moment in the 吧’s history.
Its codename was Project Ex Nihilo.
“The Creation from Nothing Project”.
I had no idea how likely I was to succeed, but I had to try. I wanted to restore the data as completely as possible.
And… I wanted to record everything I was doing now. I couldn’t let more things be forgotten.
Six months later
https://fursuit.catme0w.org officially went live.
Is this lonely performance art? I don’t know. Maybe I’ll become famous overnight because of this, maybe not. Maybe it’s just a feeling that belongs to me alone.
But at least, I saw what I wanted to see.
There’s really so much to say about my mental journey developing this project.
From the first day of development, I often wrote down my thoughts. These were originally for reference and internal sharing, but now I plan to show them to you unchanged.
Rather than recalling and retelling the inspiration from that time here, perhaps directly letting you see my thoughts, experiences, and progress from each day back then would be more real and more impactful.
If you’ve made it this far, thank you so much for your company. Please be sure to click in and read the following, it’s all the crystallization of my efforts.
Well then, enjoy reading.
Appendix: Project Ex Nihilo Roadmap
(Contains quite a bit of technical content, which may be somewhat difficult to understand for readers without relevant knowledge.)
Epilogue
If you check the certificate issuance history of my domain catme0w.org, you’ll notice that in mid-2017, the time machine’s domain https://fursuit.catme0w.org/ had already appeared.
At that time, the 吧 had just been attacked, and starting anew elsewhere was one of the mainstream voices at the time.
Many people wanted to use this as an opportunity to create forums and conduct a digital migration.
I was no exception.
Unfortunately, I’m quite certain that to this day, no one has established a forum of any scale.
But ultimately, I still saw what I wanted to see at this same domain.
If you’ve finished reading my research notes, you might wonder why the notes stopped abruptly in March.
There’s actually nothing too mysterious about this reason. It’s simply because I was too lazy, and writing the “Tieba simulator” often felt like physical labor, such as fine-tuning interface styles and so on.
However, the version officially released in June actually fell far short of the original design expectations. It was still a half-finished product.
I later went to busy myself with my own things. Anyway, this version worked for now, so I just left it there.
In the blink of an eye it was September, and a new crisis emerged for creatio (the project name of the time machine’s frontend program).
The story behind the scene of this website is truly epic, but it is still far from finished. After about June last year, I noticed there was a critical SEO failure and it eventually wiped all of itself from Google search results, and the only way to fix is a big overhaul.
One of my friend joined the development, but we immediately ran into a trouble. Something really, really bad happened, caused the overhauled version indefinitely postponed.
I am never a good programmer. You can see through the source code of the original version, but also the only version available: https://github.com/CatMe0w/creatio
I’m also not a talented one. Under the hood of this “megastructure” is shittily shitty shitcodes. And that leads to the final collapse - not the collapse of the project, but -
me.
https://twitter.com/XCatMe0w/status/1651291197112193027
https://twitter.com/XCatMe0w/status/1651291197112193027
But that’s another story.
After the Epilogue: Hope
https://www.youtube.com/watch?v=BxV14h0kFs0
“This Video Has 58,394,109 Views”
by Tom Scott
“Computer history museums are filled with the software and hardware that I grew up with and that I’m nostalgic for, because they all ran on their own, they didn’t need any ongoing support from an external company.
But if what you’re making relies on some other company’s service, then… archiving becomes very, very difficult.
So for the time being, every few minutes, my code is going out to YouTube, asking how many views this video has, and then asking to update the title.
Maybe it’s still working as you watch this.
But eventually, it will break.
Eventually, so will YouTube.
So will everything.
Entropy, the steady decline into disorder that’s a fundamental part of the universe…
…entropy will get us all in the end.
And that’s why I chose to film this here.
The White Cliffs of Dover are a symbol of Britain, they are this imposing barrier, but they’re just chalk.
Time and tide will wash them away, a long time in the future.
This, too, shall pass.
But that doesn’t mean you shouldn’t build things anyway.
Just because something is going to break in the end, doesn’t mean that it can’t have an effect that lasts into the future.
Joy. Wonder. Laughter. Hope.
The world can be better because of what you built in the past.
And while I do think that the long-term goal of humanity should be to find a way to defeat entropy, I’m pretty sure no-one knows where to start on that problem just yet.
So until then: try and make sure the things you’re working on push us in the right direction.
They don’t have to be big projects, they might just have an audience of one.
And even if they don’t last: try to make sure they leave something positive behind.
And yes, at some point, the code that’s updating the title of this video will break.
Maybe I’ll fix it.
Maybe I won’t.
But that code was never the important part. "
Acknowledgments
Thanks to the projects that provided help (although I didn’t use any of their code at all), and the friends who accompanied me along the way.
The list may be incomplete; in no particular order.
Projects
https://github.com/Starry-OvO/aiotieba
https://github.com/52fisher/TiebaPublicBackstage
https://github.com/cnwangjihe/TiebaBackup
https://github.com/Aqua-Dream/Tieba_Spider
Friends
Aster
mochaaP
LEORchn
ShellWen
NavigatorKepler
GitHub repos that I wrote for this project
https://github.com/CatMe0w/fursuit.catme0w.org
https://github.com/CatMe0w/ex_nihilo_vault
https://github.com/CatMe0w/backstage_uncover
https://github.com/CatMe0w/proma
https://github.com/CatMe0w/rewinder_rollwinder
https://github.com/CatMe0w/proma_takeout
Appendix: Project Ex Nihilo Roadmap
Early Stage - Data Extraction Preparation:
Obtain backend logs from Tieba to confirm feasibility of restoration and data integrity
- Data restoration is feasible, but it seems there’s no way to directly export complete post content through the backend without restoring the posts.
Write backend log export tool “uncover”
Export all backend logs to sqlite database while keeping a copy of the original HTML
This part is done locally, data doesn’t need to be public.
(Download uncover.db.xz)
Based on the database exported in the previous step, count the total number of posts that need to be restored and deleted again
- The spamming bots from the later period are almost indistinguishable from real human posts. Simply put, naive Bayes definitely won’t work. If analyzed manually, the workload is too large (even humans can’t distinguish them). Also, to ensure the project’s neutrality, I plan to directly restore all deleted posts in the backend logs without distinguishing between humans and bots.
Order of restoration: chronological order, from recent to distant
Order of deletion: from distant to recent
Rewrite the tool “proma” for crawling all public posts in the 吧
The original plan was to modify Aqua-Dream/Tieba_Spider, but because it’s too easy to hit anti-crawling measures,
and can’t preserve complete original data, plus this project has no open source license, and the modification workload is too large, the plan changed to complete rewrite.Plan to use selenium, single-threaded, or grid+multi-job running, save as warc archive format.Draft: Decouple the part that processes html and inputs into sqlite, then write subsequent tools to directly use warc archives as data source instead of using Baidu’s online services.- In addition to all features of Aqua-Dream/Tieba_Spider, parts that need to be implemented separately:
- Draft: Use mobile API from cnwangjihe/TiebaBackup to replace PC web pages + html parser
- sqlite instead of mysql
- Connect to proxy pool
- Crawl signatures
- Crawl nicknames
- Crawl avatars
- Optional: Crawl red text or bold formatting
Obtain BDUSS from a senior moderator for batch restoration and deletion of posts- Moderators elected by the top moderator don’t have the ability to restore posts,
this is the only way. - Opening up new horizons, see research notes for January 10
- Moderators elected by the top moderator don’t have the ability to restore posts,
With the help of the top moderator’s BDUSS, write automated tools “rewinder-rollwinder” for restoring and deleting posts
Writing this tool requires the top moderator’s BDUSS to find interfaces related to restoration.- rewinder: restore deleted posts
- rollwinder: rollback the rewinder
Mid Stage - Data Collection Night:
(Operation codename: The Showdown)
- Start rewinder to restore all deleted posts in history
- This part can run locally.
- Crawl and publish all posts
- This part will run using GitHub Actions, crawled data will be directly uploaded to releases (with sha256sum), ensuring the entire process has no manual intervention.
- Submit all posts to Wayback Machine
- After confirming data validity, start rollwinder to batch delete these posts (rollback all rewinder operations)
- This part can run locally.
- Export and publish backend logs
- This part will also use actions to run, data is also directly uploaded to releases. This data will serve as the baseline dataset for other stages in the future.
Late Stage - Data Processing and Display:
- Come up with a nice name for the project
- Write copy for the static homepage
- Write frontend interface for the static homepage
Draft: Since I don’t understand design at all, rather than cobbling together a homepage with mediocre aesthetics, consider using templates like HTML5UP or Carrd for modification.- Still need to design the interface myself
- Write frontend interface for the time machine
- Write backend API for the time machine
- Used to read datasets from uncover and proma, presenting them to the time machine frontend in json format.
If using cloudflare workers, write a tool to convert relational databases to workers kv.- kv is garbage, need to find something to store sqlite database
Late Stage Frontend and Backend Development Todo List
Frontend
- Homepage content
- Download page content
- Search box
- Interactive comment component
- Video player
- Viewer footer
- Moderation backend settings
- Audio player
Backend
- Sensible search implementation
- Rewrite and deploy to cloud
Epilogue - Official Launch and Follow-up Projects:
- Come up with better, eye-catching promotional copy to post on social media
- If the project succeeds, consider launching follow-up project: Starfield Project
- A platform for users to submit and archive extinct furry content, manually reviewed, distributed via torrent and similar methods, without breaking paywalls.
Pure Brainstorming Part:
- Burn all datasets and original
warcarchives onto M DISC or other media suitable for long-term storage, make some kind of collector’s edition (?) - Draw a furry mascot for the project (??)
Appendix: Research Notes
November 29, 2021
On a whim, went back to the fursuit 吧 to take a look. I originally thought it would still be ruins. It didn’t matter when I went back - I was half right, it’s indeed still ruins, but the moderators are gone. They left, or rather were removed by Baidu.
After waiting three years, is there finally hope?
November 30
Baidu Tieba’s backend can restore posts deleted by moderators. Almost all of 混血狼狗’s posts on the fursuit 吧 were wiped out. I don’t really believe this was Baidu’s doing. If it were Baidu, they should have made his account completely unviewable.
Right now, there’s a person who doesn’t belong to them trying to apply to be moderator. I don’t have any decent Baidu accounts left. The only two remaining ones have zero posts, so there’s definitely no hope of applying for moderator with those accounts, otherwise I would definitely get involved.
So, if that person can become moderator, perhaps I can find them and ask them to help us re-export the historical data. This way we might be able to establish a cyber Summer Palace ruins park or something, symbolizing the pastoral era of China’s fursuit culture from 2011-2016.
December 4
They got it. Currently they’re also the only senior moderator of both the fursuit 吧 and 兽装吧.
Revision: Should be “she”. Same below.
I contacted them. I’m asking if they can make me a junior moderator so I can personally access the backend and verify whether there’s any possibility of restoring that data.
I’ve considered more moderate, less conspicuous ways of handling this, but I really can’t imagine what actually happened back then - what actually occurred may be far beyond my imagination. In any case, with everything unknown, all thinking is just fantasy. Everything can only be judged after accessing the backend.
I hope to not change the current state of the 吧 as much as possible, just copy the data and establish my own cyber ruins park not controlled by Baidu.
If I become a moderator, I should be able to extract all the data, or at worst extract titles. Data cleaning will definitely be troublesome though, since there should be quite a few spamming records.
Next I’m planning to buy a domain name and open a website to store the data. Packaged data will be distributed via torrent. Now I need to write some copy.
This is exactly what 艾斯吧 did, and we’re about to do it too!
(“艾斯吧’s revenge - a huge revelation that made everyone laugh” https://zhuanlan.zhihu.com/p/159644849)
December 6
I’m in.
All my guesses were confirmed. The scene presented by the backend is indescribable, almost bizarre. 混血狼狗’s posts from the pastoral era were indeed completely wiped out. The operator was an account called “play月光如水k”. I’ve never seen this account. Who are they?
Including “play月光如水k,” several accounts like “飛翔之龍” and “大召唤之门” no longer exist. They deleted their accounts. There’s something even more peculiar: during 2018, the Baidu account “糊狸狐兔” now shows as “AbramsDragon’s” name. I can’t think of any reasonable explanation for this.
I shouldn’t waste more time trying to reconstruct the chaos of 2018. Even if I figured it out, what would it matter? It would just stir up another storm of drama without solving any problems.
Only one thing deserves attention: data. Data integrity.
December 7
I spent three hours deploying this software. PHP and URL rewriting are really annoying. Thinking that programmers and ops in the past had to deal with these things, I’m grateful to be living in such a good era.
https://catme0w.org/ekr3ceijfeac6e2iyjt4d7f4/
This thing can project the 吧’s backend to the public internet, so I can show some other people what really happened back then. Of course, I’m not sure who to send it to yet.
Honestly, I don’t really want the past moderation team to get involved in this, otherwise it might affect the (public opinion) neutrality. The entire project’s position in public opinion is very important. After all, anyone with eyes can see from the backend logs what happened. I must remain invincible in public opinion, there must be no risks. Although, to say who in this world deserves the right to know about this most, it can only be these veterans who personally experienced it.
This program is just a temporary interface. How to collect, restore, and organize the data afterward is probably a difficult problem.
First and foremost, the deleted posts we see from the 吧 backend - if they’re thread posts, we can only see the first few words of the OP, the rest is completely invisible. To access these records, we must restore the entire post, which inevitably means modifying the current 吧.
If we look further ahead, suppose we use this method to view all deleted posts, it means we need to restore them all. This would absolutely be another level of devastating blow to the 吧.
Of course there’s another method: restore all posts, crawl them, then delete all the originally deleted posts again.
The flaws of this method are also obvious: first, all people who had posts deleted will have their “system messages” spammed by us; more seriously, such operations would make the 吧’s backend logs completely unrecognizable. The biggest problem is, after such reality-reconstruction-like operations, how can we guarantee the entire 吧 truly returns to “how it was before we came” - simply put, we would be at a disadvantage in public opinion.
So now the main problem is urgently needing to find a way to obtain the complete content of deleted posts without restoring them.
Then there’s the less serious problem: what kind of archive should we build.
Now, suppose we can already export complete content of the 吧’s deleted posts, no matter what method is used. My original idea was to only establish a “snapshot” around 2016 - the state of the 吧 at that point in time. But after personally accessing the backend, I found this is actually very difficult: to accurately restore to the 2016 state, all logs in the 吧 backend must be analyzed; the results obtained by individually rolling back all operations of a certain person are inaccurate.
So why don’t we directly implement a more ambitious goal: combine the current 吧 state with all backend records to create a “time machine” that can trace back to any moment in history.
This raises a new question: after we create the time machine, what about new posts and operations that appear in the future? We’ve already exposed everything about the 吧’s past, including every operation by every moderator.
Simply put, we’ll make the 吧 lose its future value of existence.
To solve the above problem, I considered a less radical solution:
Suppose we ultimately can’t find a way to extract complete content without restoring posts, then we can only completely roll back the behavior of certain deletion bots to restore some of the most valuable posts, most of which are from 混血狼狗.
However, next, everything we do will fall into an extremely awkward state: since the 吧 has been restored, why go out of the way to view civilian backups?
For us, of course it’s not like that. We know Baidu’s lack of bottom line, backups must be made; but most people don’t realize this, or even if they can, the differences in access speed and ease of use alone can make most people give up.
Now it’s very likely impossible to find a perfect solution, making trade-offs is probably inevitable.
More urgently than this, there’s another problem: must quickly support two more moderators to take office.
Currently the other party is still active in 兽人吧 recently. Abandoning the fursuit 吧 is very likely just an accident. Based on past experience, furry-genre 吧 with only one moderator are very easy to be reported and taken down. I originally didn’t want to become a moderator myself, but considering large-scale post restoration operations may be needed, I might have to do it myself.
So, need to find another person, and even prepare several alternates.
Next step: Completely extract the current state of the 吧 backend and all publicly visible 吧 content. Although the specific direction is still not completely clear, some things can be started first.
Precisely because the code is ancient, Baidu Tieba’s frontend hardly uses js, which means I don’t need to use selenium. Just download html with requests, then feed it to an html parser to produce the data structure we need.
December 8
https://github.com/CatMe0w/backstage_uncover
The prototype of the backend log export program is already done. I chatted with a technical advisor yesterday, and the plan is to use sqlite for storage.
Actually, I didn’t think about databases at all at first. After he pointed it out, I realized the problem. I originally planned to just casually save it in json, but the data volume might be very large - hundreds of thousands of rows is just basic operation for sqlite, but hundreds of thousands of rows of json would choke, not to mention the query time difference.
I’m considering letting github actions run and export the data after the program is perfected. This is mainly a public opinion consideration. Because honestly, the stuff in the backend records is just too… unbelievable. I won’t say the ugly words, you get the idea.
Letting actions run means running the program in the repository at that moment. After crawling the data, it’s directly uploaded to releases with sha256sum attached, ensuring that from code to runtime environment to the final release process, not a single link can have manual intervention or data tampering.
The HTML of the 吧 backend is also truly indescribable. The HTML structure is fairly regular, but some data is always short or presents itself in a mess. For example, some <li> text has fifty or sixty spaces before and after it, or the posting date doesn’t provide the year, etc.
For the year problem, we initially planned to crawl posts before and after the corresponding post to calculate the year from nearby posts, but obviously this has poor robustness, and crawling too much might hit anti-crawling measures.
Aqua-Dream/Tieba_Spider’s crawler seems to quite suit our needs for crawling public 吧 afterward. The main disadvantage is that it uses mysql instead of sqlite. We don’t need mysql.
I tried running this program. The situation is more severe than we imagined: currently the 吧 has 34 pages total. If all deleted posts are released, this number needs to double; and this program gets blocked by anti-crawling captcha when crawling at most no more than 29 pages.
For my local environment, this is easy to solve - connect to my proxy with load balancing. But for actions, the situation is much trickier. After looking at related issues, the most reasonable solution should be to modify the code and connect to a public proxy pool.
Combined with some suggestions from the technical advisor, the operation route going forward is basically confirmed.
Currently the total number of operation logs is 5126, of which “delete post” accounts for 4291 entries.
Find a quiet late night and restore all deleted posts. After completion, completely crawl the entire 吧, then delete the restored posts back. From the outside it looks like nothing happened, except some users’ “post deleted notifications” might get bombarded.
This method is indeed a bit absurd, but under Baidu’s extremely poor management system and programming level, this should be the best method.
Finally, crawl the backend operation logs again, merge the two datasets, and basically have the complete record of the 吧’s entire history (except what was deleted by Baidu, which moderators can’t see either, no one can see).
After getting all the data, this stage is complete. Subsequent work will be completely independent of Baidu’s services.
December 9
Another advisor suggested I save warc archives.
warc is a format similar to mhtml that can maximally preserve the loading process and data of a web page. Also, with warc, we can even upload to wayback machine in the future (ensuring the entire crawling process is trustworthy, the actions running mentioned earlier).
But the problem is, Tieba_Spider doesn’t use a browser, so it’s impossible to save replayable warc. What Tieba_Spider does is simply download html, extract specific text, then input into database.
If warc is needed, I need to rewrite the entire tool.
I thought of an ingenious but actually very stupid method to determine posting year: find the first post of each year in the entire 吧, hardcode their ids into my code, so I can accurately determine the year without initiating any additional network requests.
If using manual binary search, finding these posts should be quick, but actually this process took me over an hour. Because during manual traversal, I found that at least 90% of the posts in the entire 吧 have disappeared.
Specifically, 90% of the ids are empty. Most of them were deleted, a small portion are “account hidden,” a small portion are blank errors, and one is “吧 merged.”
So we’ve lost 90% of the past.
December 10
While fixing the remaining bugs in uncover, I’m gradually getting so angry I could have a brain hemorrhage.
I found a batch of anonymous IP users posting in 2019. Where did anonymous users come from in 2019? How many edge cases do I have to handle for this garbage product that is Tieba?
Tieba_Spider has other problems. It can’t crawl nicknames, and if only using usernames, it’s obviously very inappropriate. Many people change nicknames precisely to stop being stuck with a username that’s like their awkward history.
The web version of Tieba doesn’t have a frontend-backend separation architecture. If crawling using the PC version, need to process html. There’s a crawler using mobile API, but its functionality doesn’t completely overlap with our needs: cnwangjihe/TiebaBackup
Using mobile API might be able to avoid anti-crawling…?
The answer is no. The mobile API also hits that stupid rotating captcha. The technical advisor wants to face this captcha head-on and find a way to automatically recognize it, but I actually advocate bypassing it with a proxy pool or selenium.
All code for this project must maintain the simplest and most straightforward design, especially absolutely no showing off. Showing off inevitably introduces complexity, and once complex, the probability of instability increases.
Bad news: Baidu Tieba now only allows applying for one moderator. This company really stops at nothing for traffic.
Finding the current moderator has become the only path. Can only hope they’re willing to help me.
December 11
Looking ahead a bit to future plans, after the database is ready, the website needs to go online.
The static frontend is planned to use cloudflare workers, and the database backend also uses workers. But there’s a problem - workers’ data persistence solution is called kv, which is a blood pressure-raising thing. Simply put, kv is like a Python dictionary, and this thing also has capacity limits, each entry can’t exceed 100 MB.
So, directly stuffing the database won’t work, converting to kv format won’t work either. Must seek other alternatives. I really don’t want to deal with servers. Workers are much cheaper, and if operated properly, might not even cost a penny.
Workers officially endorsed several third-party database services, and prisma among them happens to support sqlite. But don’t know what prisma’s fees are like. Logically, over a hundred thousand rows should just be a drop in the bucket.
Seems like prisma is completely not what I understood it to be. I guess I’ll just pay cloudflare. Anyway, it’s cheaper than buying a server yourself no matter what, and mainly don’t have to deal with ops.
Tried using webrecorder’s pywb to archive several pages of the 吧’s raw data, warc format.
Quite a few problems… First and foremost is data volume. After crawling two or three posts with images, even gzip compressed data volume reached 115 MB. If crawling the entire 吧, uploading this scale to releases would be quite unfavorable.
Secondly, pywb’s web proxy has difficulty handling some of the 吧’s js. Some controls and buttons malfunction.
Finally, what I find most troublesome is that the 吧 has a huge number of ads and occasionally pops up demanding login. I usually have adblockers on, so I had no idea about this. When the time comes, it’ll be unattended headless selenium running. To send an adblocker in and add Easylist+Chinalist before formal crawling - how easy is that?
I’m running out of tricks.
December 12
uncover is complete. After several rounds of testing, it can be considered GA (generally available).
Worth mentioning, the 吧 backend doesn’t seem to have strict anti-crawling like the public 吧, but occasionally timeouts still occur.
There’s still no progress on crawling the public 吧. Perhaps now it would be more appropriate to shift focus to the frontend interface or copywriting?
December 13
The project’s progress has indeed slowed down. Today was almost standing still.
I remembered an advisor mentioned before that he crawled 100 pages in a real browser using js and never hit anti-crawling. I asked about some operational details at the time. He said he need to test again specifically for my needs to know for sure.
Awaiting his good news. These two days I’ll focus on the publicly visible parts.
December 14
Someone suggested considering abandoning the warc format, but there’s one person who insists on saving all original web pages to Internet Archive Wayback Machine, so there’s no way to abandon warc.
Wayback Machine is particularly unfriendly to Baidu Tieba. For example, from 2016 or 2017 until now, all the 吧 content crawled by Wayback Machine itself shows green bubble 30x redirects, actually not saving any content, things like that.
Therefore, saving warc ourselves and then uploading through teams certified by Internet Archive became the only viable path.
December 16
After discussions among several advisors (with me as the communication bridge), and also pulling in Archive Team’s IRC together, we finally clarified the route regarding warc format, which is -
Abandon warc.
Specifically, abandon us personally crawling and saving warc using browsers.
Over the past few days, we several people each did research and observation on the behavior of Baidu Tieba web pages in browsers and various archivers. We realized that “perfectly preserving all data in warc archives” may not be feasible at all. Even if it is, development is extremely tricky.
Besides the ad problem already mentioned above, the biggest problem is the login wall. The most intuitive manifestation of the login wall is in sub-post replies.
Suppose a post’s sub-post has 11 or more replies. At this time, the sub-post will split into two or more pages, with a maximum of 10 replies per page; without user action, the first 5 are displayed. Users can click “expand” to see all 10 of the first page. The login wall behavior is like this: without logging in, you can only see the first 5, clicking “expand” pops up login prompt; after logging in there are no restrictions, you can view freely.
In the web page’s internal logic, the sub-post component rendering doesn’t start until the user scrolls to the corresponding floor, but this process doesn’t depend on network connection. Actually, the moment the post is opened, an xhr is sent to (Tieba main domain)/p/totalComment, the return value is the first 10 entries (first page) of each sub-post on the current page, in json format, but doesn’t include the second page and beyond. Loading the second page of sub-posts is a separate xhr, the return value is a bunch of html - the html of the second page.
Corresponding to our various archivers and crawlers, the situation is roughly like this: without logging in, sub-posts can only see the first 5; if the client has a Tampermonkey user script to bypass the login wall, at most can see 10.
Of course, we can definitely find a way to send in login state, using my account or whoever’s account. But content crawled this way is obviously very unsuitable for uploading to wayback machine - imagine seeing a username in the top bar, a username in the sidebar, and a bunch of message notifications for this user in wayback machine’s archive. It looks absurd no matter how you look at it.
More importantly, this is quite difficult technically. First, how do we send login state into the program? If using wayback machine api (if it exists), I’m not even sure if it’s feasible; if it’s a program we run ourselves, like browsertrix crawler or manual pywb, how do we get a bunch of cookies into actions? Hardcode them into the code? Don’t forget, this part of the program needs to be run by actions, otherwise there’s no way to prove the crawling process is trustworthy.
That’s not all. After the program manipulates the browser to finish loading the web page, it still needs to scroll down, still needs to process html, to click those “expand” and “page turn” buttons one by one. Holy shit, just saying this I already feel the complexity is unprecedentedly large. Moreover, to implement this function, highly automated solutions like browsertrix crawler definitely won’t work. pywb+puppeteer or pywb+selenium, pick one…
Can’t do it, can’t do it. Only upon this review did I realize what a huge pit we originally wanted to dig.
Suppose we really completed all of the above, we’d discover a huge surprise - the input and output are completely disproportionate.
How many posts have sub-posts? How many sub-posts with more than 5 entries that need pagination? This number definitely won’t be large. Compared to implementation difficulty, abandoning is the better choice. Moreover, wayback machine itself can already archive all data except these sub-posts. We really don’t need to do it personally.
We really can’t have everything and do it perfectly. Trade-offs are necessary.
P.S: When encountering the ad problem before, I considered whether ads divs could be manually removed later. Obviously, this idea only existed in my brain for less than three seconds - archives that have been manually processed are not authentic archives and thus lose the value of archiving.
So, can we only save warc for our own use and not upload to wayback machine? This idea only lived two seconds longer than the above. After all, with the self-developed™ time machine, no one will want to replay and browse through those warc files.
P.P.S: The green bubble mentioned in the last research note is actually the 吧’s directory (吧 homepage). After testing, posts can be crawled normally. That’s enough.
January 10, 2022
- Part I
Haven’t updated in a while, but actually I haven’t been idle. Been continuously updating proma in a toothpaste-squeezing fashion.
But honestly, you can tell from my state. I don’t want to write proma.
With the mobile API’s help, proma’s development difficulty has decreased a lot. It’s just that there’s one part that the mobile API can’t reach.
Simply put, floor text crawled by the mobile API will swallow blank lines. For example, if one or many lines are blank between two paragraphs, you can’t see it in the mobile API. The two paragraphs will be pressed tightly together. This is actually also the mobile app’s behavior.
This is very ugly, and more importantly, there’s information loss. And this loss shouldn’t happen, so must find a way to fix it.
My idea is to first use mobile API to crawl floors, enter into database, then use the web version to crawl all posts again, replace all text with versions with correct blank lines, and supplement signatures along the way.
The mobile crawling part is quite simple, can even be said to be a kind of enjoyment (compared to processing Tieba’s HTML). The data source is proper JSON. Although there are problems like chaotic naming and mixed in a lot of redundant data, the flaws don’t obscure the virtues. Much more comfortable than processing HTML.
But after all, still have to deal with HTML in the end. Honestly, I really don’t want to write this part, and I’m also at a loss. Over these many days, I haven’t thought of a reasonable route to implement it. Actually, it’s better to say I really hate Baidu’s HTML too much.
Then there’s a huge hidden danger I only recently realized - I don’t think the moderator is very likely to just hand over their BDUSS to others. Because I only now realize that BDUSS isn’t a token specifically for Tieba, but for all Baidu products.
For example, Baidu Netdisk.
If it were me, I would never give BDUSS to others no matter what, let alone to an internet friend who isn’t very familiar.
Then I thought, although I couldn’t find publicly available post restoration interfaces from others on Google before, maybe I can look on GitHub? As long as we can find the interface, we can make rewinder. After that, just give the finished rewinder to the moderator to run, no need to let BDUSS leave their computer.
And I really found it -
And next, we perhaps welcomed the first good news since the project was established.
- Part II
This is the code with the post restoration interface. I looked for this interface for a long time. Originally thought I had to personally get the senior moderator’s BDUSS to find it. Now it’s not needed.
However, compared to what’s about to happen next, finding this treasure of a post restoration interface actually seems somewhat ordinary.
The surprise is in this repo’s README.
Excerpt:
“Developed based on client version api, which means moderators elected by the top moderator can also ban for ten days, refuse appeals, unban, and restore deleted posts (requires top moderator to allocate permissions).”
If he didn’t lie to me, this means I no longer need to find any senior moderator’s BDUSS, and don’t need to give the program to the senior moderator to run when the entire process can’t be debugged or tested.
I can complete everything.
When I saw this line, I almost cried. It’s been over a month, have we ever encountered good news? But today, we finally have a surprise, a miracle.
Of course, there’s also one thing that makes me slightly unhappy, which is that I found the method to crawl the post directory through mobile API in his code.
Following a basic theorem: Tieba’s mobile API is always better to handle than the web version. I spent a long time on the web version crawling post directory, which will definitely have to be abandoned. But it must be abandoned - the mobile API’s robustness is much better than my web-crawling grass-patch framework.
Just wasted several days. A bit annoyed.
Next thing to do is to confirm whether he lied to me, whether I can really restore deleted posts.
Revision: No offense meant to senior Starry-OvO! It’s just that this was originally private notes, so a bit unguarded in speech.
January 24
Unfortunately I couldn’t find the method for “little” moderators to restore deleted posts, but the author of Tieba-Cloud-Review left only one contact method on their user page: email. I tried to contact the author through this email, but it’s been almost two weeks with no response. However, with the help of interfaces in his code, rewinder should be directly usable. When the time comes, just hand the program to the senior moderator.
Although the fault tolerance of preliminary work is still extremely low, at least it’s not completely without a way out.
In addition, the method of obtaining post directory through mobile API is not feasible. There are posts that are only invisible on mobile, and the proportion of such posts in the first two pages even exceeds 5%, reason unknown.
雪风 threw me a bunch of local archives of some quality posts from back then, produced in 2018. It’s the kind saved directly in the browser with Ctrl+S in the form of “title.html” plus “title_files” folder. Actually the data volume is less than I imagined. Can be used to test several programs in preliminary work, and doesn’t conflict with my later route.
Will probably make it into a torrent later and distribute it together with my data.
I spent several days writing an algorithm to fix blank lines in text. The algorithm is very complex, was overthrown and redone several times, but can still only satisfy several (though majority) special cases. Robustness is actually very poor.
Meaning is, it works for now, but I’m completely not at ease letting it run in production.
At the same time there’s also a new problem: red text and bold. Forgot about these two things before.
But for the current fix algorithm and program logic, how to fix bold and red text can be said to have completely reached a dead end.
At this time someone enlightened me. They roughly said: if it were them doing it, they would directly save the web version HTML as-is into the database.
Me: *falls into contemplation*
What they said indeed makes sense. If directly using HTML for database entry, no longer need to do any complex fixes. Even if there’s Baidu’s garbage data mixed in, it can be easily removed, or fixed in real-time on my web page later.
This means the data collection part of “proma” for preliminary work will immediately mature; preliminary work will immediately end, late-stage web page and backend work can soon begin.
Why did I fall into contemplation? Because if switching routes like this, nearly half of the existing code will be abandoned.
But to obtain the best possible data, cutting losses is inevitable.
January 29
2022-01-29 01:50:57,518 [INFO] Current page: posts, thread_id 7648701681, page 1
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_top" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_01.png);height:17px;"></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_middle" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_02.png)"><div class="post_bubble_middle_inner">加油</div></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_bottom" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_03.png);height:118px;"></div>
elif item.get('class') == ['post_bubble_top']:
return None
# Directly give up on posts that used weird bubbles
# This project's complexity has long exceeded my expectations. According to plan, the project's scale should never have expanded to the current situation
# As edge cases requiring special handling keep increasing, the program's robustness is also visibly plummeting
# Posts that used weird bubbles are mostly replies, and often don't have complex formatting, plus their quantity is very small
# So, for this type of post, just keep the content in the original database
January 31
Hey, Happy New Year. Today, proma is officially GA.
This came later than I expected, but compared to the project’s current complexity, it’s actually reasonable. Moreover, it happens to be on New Year’s Day, so it’s also auspicious.
Preliminary work is nearing its end. What needs to be done next is to check the remaining bugs in preliminary projects, conduct multiple full tests, and ensure operational stability.
After everything is complete, proma and uncover can be sent to GitHub actions.
February 5
proma’s existing code is already perfected. Unless major changes are needed, there shouldn’t be much left to touch.
I established a private repo to test actions. This thing can’t be expected to succeed the first time.
However, when the program was more than halfway through, bad news came. The program on actions threw a weird error. Because the process exited abnormally, actions directly interrupted the subsequent packaging and uploading process, forcing me to spend another hour or two doing full testing on my own computer.
The local testing stage was lucky - successfully reproduced the error consistent with the online environment. However, being “lucky” revealed misfortune: Baidu Tieba’s rate limit (captcha, anti-crawling, pretty much the same thing) resumed operation.
What does “resumed” mean? It’s like this: since New Year’s Eve until yesterday, Baidu Tieba’s anti-crawling mechanism seemed to be completely shut down - test processes over the past few days were unusually smooth. Even multiple consecutive full tests never encountered rate limit even once. Before this, Baidu Tieba had what could be called a brutal anti-crawling mechanism: suppose not going through mobile API, you’d be blocked by captcha within 30 requests.
This problem isn’t unsolvable. The general method in the crawler industry is to directly hook up a proxy pool, switch to the next IP when one goes bad. For me, just send my proxy into actions together and turn on load balancing. proma’s code all uses https and enables certificate verification, so even with a proxy there won’t be MITM suspicions.
It’s just that this way, the workload increases again.
And even more regrettable, we missed the optimal launch window.
Some other things to say
This project has been ongoing for exactly two months. Look at how much I’ve put into it in these two months:
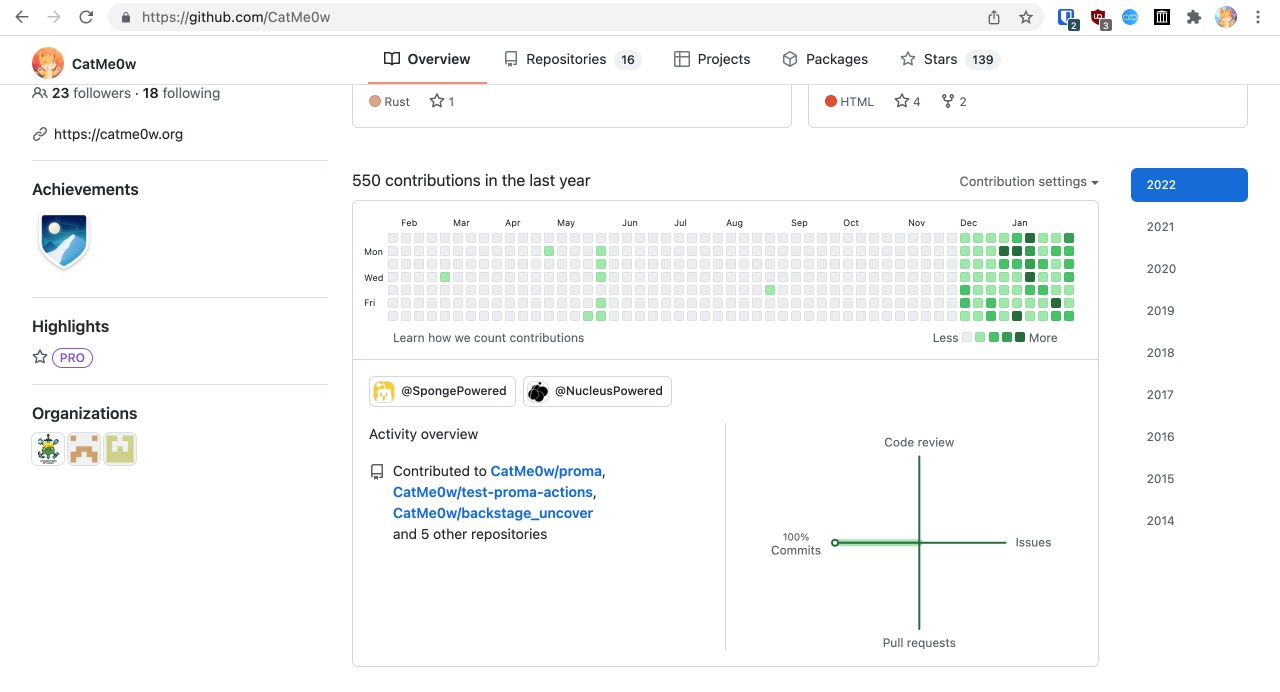
Directly created all-green tiles since December.
All-green means new code commits every day.
I have huge enthusiasm for this project because I really, really want to see the past times.
Furry, now also called 福瑞 (in Chinese internet culture), experienced explosive growth around 2018-2019. The scale of the furry community became unprecedentedly large in a very short time, and this quantitative change also caused qualitative change - furry, as if overnight, became known to everyone. Now, if you randomly find someone on bilibili, they probably know what “福瑞” is; even quite a few of my elementary school classmates already know about furry.
Actually disharmonious signs have long appeared within furry. These signs are precisely the side effects brought by the explosive growth. For example, before furry was widely known to the public, discussions about “getting younger” and “callout culture” had already appeared internally.
During the project’s development, I saw traces left by people from the past, many many. The community was truly small back then - in 2013, the fursuit 吧 didn’t even have a thousand people. And more importantly, discussions were truly harmonious. In the first few years when this subculture just entered China, everyone held hope and enthusiasm, discussing details of making suits or sharing videos from YouTube, and there would never be drama or callouts.
We can’t go back, but at least we can still have it in memories. These memory fragments keep motivating me to continue, determined to finish this project, even if in the end only I want to see it, I’m satisfied.
…However, this isn’t all. If it were just such a pure purpose, I wouldn’t need to bother with actions and proxy pools. However, what happened to the fursuit 吧 during 2017-2018 makes it necessary for me to bother. This is also my other half of motivation.
Let me tell you what I actually saw in the 吧 backend: after the 吧 was usurped in 2018, the newly appointed moderator was someone we’d never seen before. And what was his real identity?
A spamming bot.
He’s not furry, not even a real person, just one of many purchased bot accounts.
And “飛翔之龍” and others who organized campaigns against 混血狼狗 elsewhere, their accounts were also used for spamming.
The first thing the “bot moderator” did after taking office was to destroy traces of their own people’s spamming, and at the same time took away all of 混血狼狗’s posts. Our history was gone.
I’m really angry, but in 2018 they indeed grasped public opinion, and we couldn’t take back the 吧 and history at that time.
Being able to get today’s opportunity, I’m determined to reveal all of this to the world. Precisely because of this, I can’t leave them even the slightest breakthrough in public opinion. So I thought of using the automated program “GitHub actions” that isn’t subject to manual intervention and open source software to prove my project’s impartiality.
A code review buddy asked me, why go through all this trouble? You’re way too much of a clean freak.
I think I have no other choice.
(In the future I might selectively make parts of this article public. Obviously this section probably definitely won’t be in the public scope)
February 6
I take back what I said in the last entry about “Baidu Tieba relaxed anti-crawling mechanisms during New Year.” Because I just discovered that my Windows computer apparently never encounters anti-crawling captcha at any time, but both my Mac computer and actions do, and the speed of encountering captcha is very fast.
And the reason I drew the conclusion in the last entry was probably because during New Year I used this Windows computer for development and testing, so didn’t see captcha at all.
Bizarre, truly bizarre.
All platforms use the same code to run, even my Mac and Windows computers are on the same IP. Where exactly is the difference?
Fortunately, after seeing the anomaly on actions, I chose to switch to Mac for full testing, otherwise it would be impossible to reproduce this problem. It would truly become “pathogen won’t reproduce in laboratory environment.”
If I can find the secret of this Windows computer not being restricted, won’t need to bother with proxy pools, and running speed will be faster.
Wait, let me read yesterday’s article again, what did I say?
“飛翔之龍” was used for spamming
Everything seems to make sense now! I suddenly understood the connection between these similar accounts.
Since “飛翔之龍” was used for spamming, whether there’s potential risk of account termination or there’s already account restrictions from Baidu, since it’s to be used as moderator, the user behind this account definitely shouldn’t continue using this account with a “record”.
If my hypothesis is correct, then this can explain why 飛翔之龍’s account has been deleted, while the later fursuit and 兽人吧 moderator “AbramsDragon” used exactly the same avatar as 飛翔之龍. It’s basically reanimation.
And “飛翔之龍” we’ve already confirmed is simultaneously “大召唤之门,” “软毛蓝龙驭风,” “软毛的须臾,” etc. Many alt names, just listing a few common ones.
There’s still one doubt remaining, which is that the current “AbramsDragon,” whose previous username was “糊狸狐兔,” and this account was used in 2018 to organize campaigns against 混血狼狗.
Now you can still see the original battlefield through this link: https://tieba.baidu.com/p/5686874465
混血狼狗’s archive of the battlefield in 2018, you can see it was indeed “糊狸狐兔’s” name at that time: https://www.bilibili.com/video/av23138512
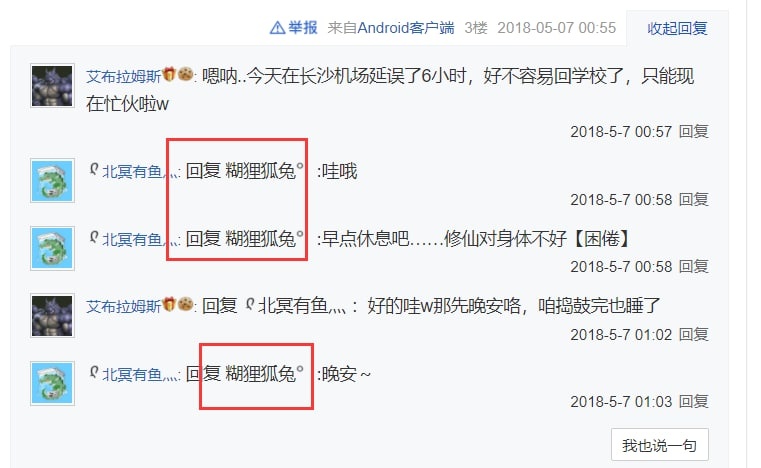
Revision: This post has been deleted. Perhaps I spooked them after making these research notes public, or perhaps they’re just infighting again? Anyway, I’m putting an Internet Archive link here:
https://web.archive.org/web/20220328163719/https://tieba.baidu.com/p/5686874465
Back to the main topic, currently I don’t have any clear evidence that “飛翔之龍” and “糊狸狐兔” are the same individual (language style differs too much), but at least can determine the two are closely related.
To everyone who sees this line: If the project hasn’t been publicly announced yet, absolutely don’t spook them! At least only after data collection is complete can we publicly reveal this project’s existence. I’ll first complete data collection, then complete the static homepage (portal website homepage). Only after the static homepage is complete can it be made public.
Although my initial hope was to release after everything is ready, the time machine later might have a long construction period. If it really doesn’t work, announcing early isn’t impossible either.
February 13
A month passed, and I finally received a reply from Starry-OvO.
He didn’t lie to me! “Little” moderators really can restore posts, and there’s even a “single request batch restore” interface, just because the demand was too small, he didn’t make it.
To give moderators the ability to restore, need to be on mobile, with top moderator setting it in 吧 info. This option doesn’t exist in the PC version backend. In fact, mobile and PC’s Tieba backends are two complete and independent systems. The PC version backend doesn’t even support https, probably hasn’t been actively maintained since 2012. No wonder I couldn’t find any related signs on PC before.
Even better news is that I can definitely operate personally. Work fault tolerance has greatly increased.
February 17
There’s no time like the present, time to start action.
rewinder is very reliable, succeeded in one try. Now, all viewable previously deleted posts have been completely released. I also immediately launched tests of proma and uncover in local and online environments.
proma needs quite a few changes. Among the released posts, many are from ancient times with all kinds of weird data structures. Need to spend some time specifically adapting.
Good news is, the first page of posts is completely unaffected. Unlikely to be discovered by people in the short term. This means my time is much more abundant than expected… Of course, except for posts deleted in recent days. Hopefully they won’t notice this discrepancy.
There’s another thing that amuses me. They bought quite a few finished spamming services back then. The forty thousand level-1 accounts stuffed into the 吧 were their masterpiece. It’s just that these pure bots have been mostly blocked by Baidu, so the traces of spamming produced by these “external aids” aren’t very obvious.
But here’s the exciting part - this group also used their own main accounts to connect to spamming programs, thus creating a spectacle: While they were spamming in the fursuit 吧, they were simultaneously doing the opposite in 兽人吧, organizing campaigns against 混血狼狗. And now, the traces of their spamming that can still be observed are even more than pure bots.
Really hilarious. How dare they, how dare they directly use the same account for spamming and callouts…
With unprecedentedly abundant data, I spent some time searching for those ancient drama battlefields, trying to completely figure out the personnel structure of the spamming group back then, commonly called LL.
Combining Internet Archive, local database, 混血狼狗’s videos, and the current 吧 state, I finally completely confirmed: 艾布 is 软毛.
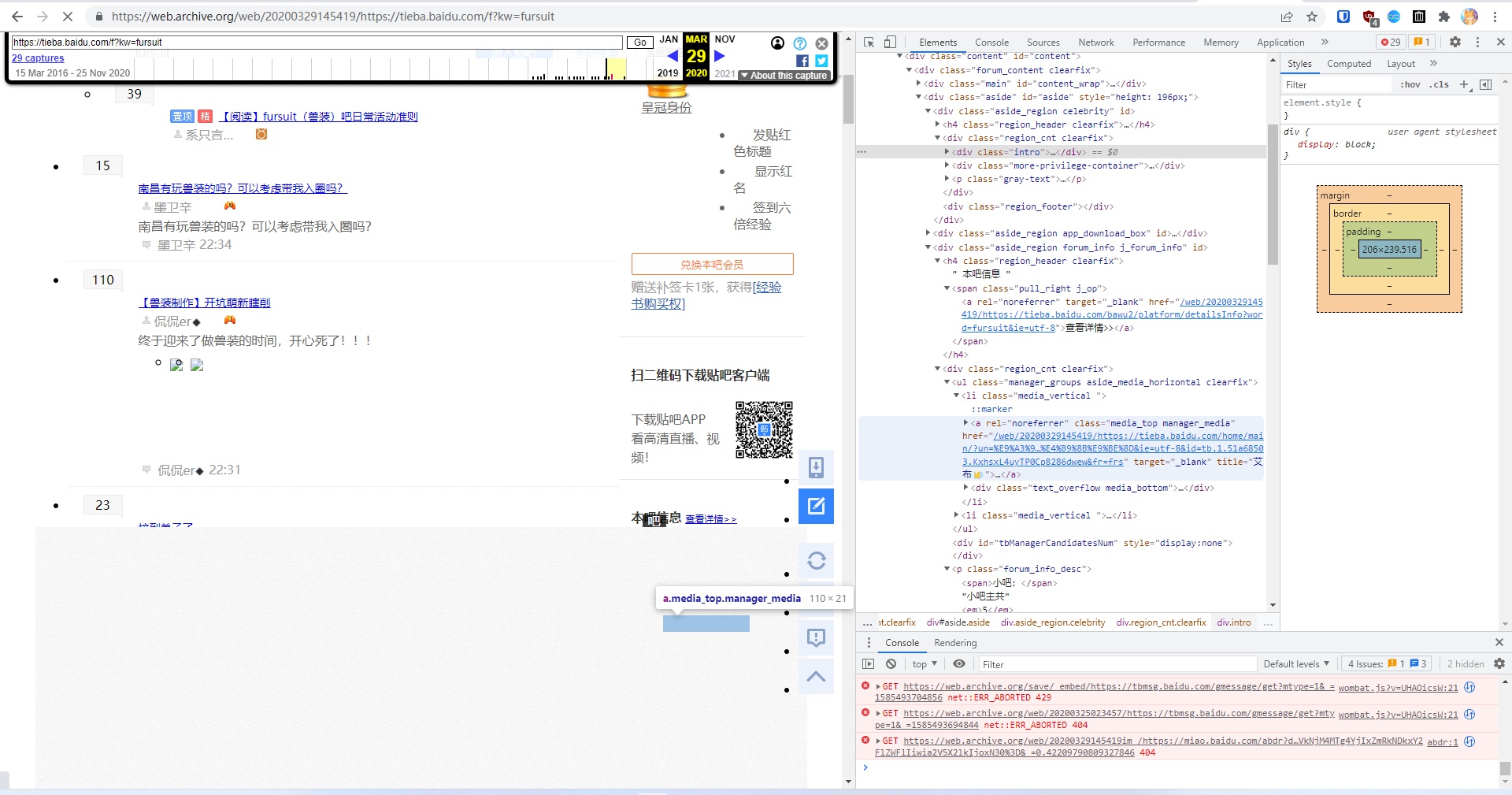
Internet Archive’s archive from March 2020, formatting is messed up, moderator’s avatar is obscured, but through the link you can see “艾布’s” name

Moderator’s user link, “艾布’s” name appears. Note this tb.1... part, this is one of Baidu account’s unique identifiers
Avatar seen after removing obstruction. 软毛 (“飛翔之龍”) used the same avatar
“飛翔之龍’s” spamming post. After account deletion, name is no longer visible in public 吧
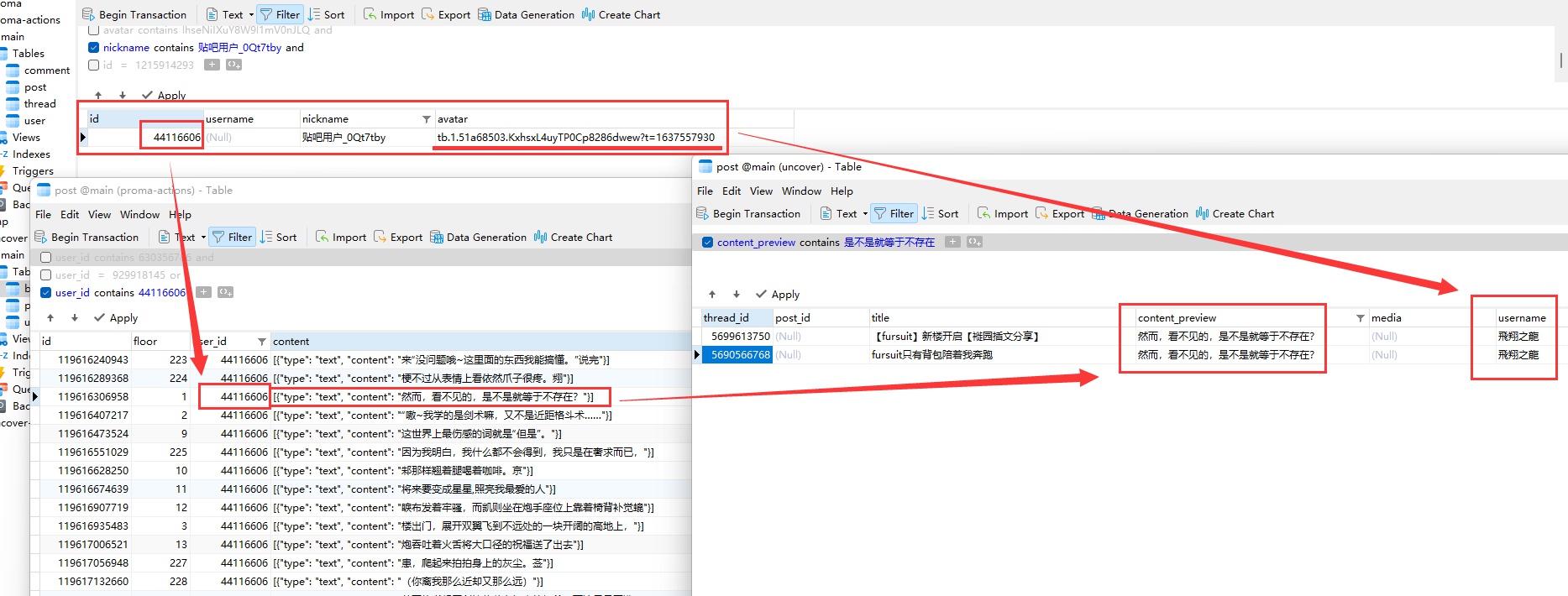
Record found from database. Explosive poster’s username is “飛翔之龍.” The tb.1... field is the same as March 2020 moderator “艾布,” i.e. same account
(Thanks to Internet Archive for the assist)
But I still haven’t figured out the real connection between “艾布拉姆斯” and “糊狸狐兔.”
This is an internal document, not public. I’ll just say it directly: if making a case, just hammer them as the same person. After all, the following can’t be whitewashed (though it might also just be the same person):
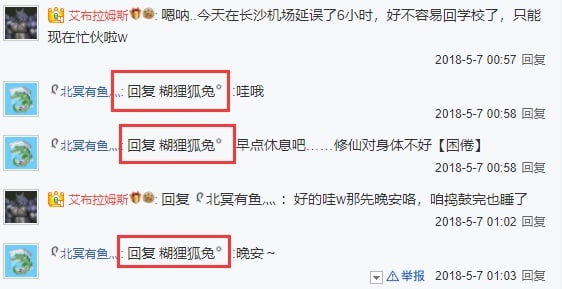
Obviously I can’t personally go down and organize campaigns, but we’ve finally regained the right to speak. We already have the ability to counter-attack.
Revision: This analysis is completely wrong. See: https://www.zhihu.com/question/327443124/answer/709795424
February 27
Mid stage is complete.
Now, all temporarily released posts have been deleted back. The 吧 has returned to exactly the same state as before December last year.
The late stage mainly consists of two parts: frontend and backend, which is our self-designed “Tieba simulator.”
Frontend is the web page, for end users to see; backend interfaces with the database, processes database query results, presents them to the frontend, then the frontend displays the images.
After no longer having so many unstable factors from preliminary development, finally can do some fun things in the late stage, like trying the latest and trendiest technologies…
March 26
I’m too lazy, too lazy to update research notes.
In any case, backend development is complete and online. This means late stage is half complete. As long as frontend is complete, can officially release.
The backend development process was actually quite difficult. This thing needs to implement logic much more complex than my initial expectations. Encountered quite a few difficulties midway, but ultimately pulled through and created a usable finished product.
Now, frontend development has just begun. Messing with Node.js and that whole bunch of stupid packaging tools and package managers wasted an entire day. Frontend development really is a very, very, very unhealthy community. Every few months, a batch of projects you’ve never heard of appear on GitHub, each with 2000+ stars; each new project has the grand dream of “cleaning up all the past shit mountains,” but their destination is always to become part of the shit mountain, then be attempted to be cleaned up by new shit mountains, and so on.
But ultimately regarding tools and frameworks to use, I still have a clear idea. Then came the second difficulty of frontend development: graphic design and copywriting…
Design and copywriting are so difficult to do that even though I started this during preliminary stage, still haven’t written a single word. Although overthrown several times midway.