fursuit吧:档案馆与时间机器
本文原载于「fursuit吧:档案馆与时间机器」项目主页。
嗨,我是猫喵,「fursuit吧:档案馆与时间机器」的作者。首先,感谢你看到这里!
“档案馆和时间机器”是我投入最大的项目之一,这既是一次为furry(尽管主要是fursuit)“寻根”的尝试,也是我送给自己的礼物——一直以来,我都非常渴望能够修复这些,本来以为早已永久丢失的数据。如今,我终于得到了它,而创造这份礼物的不是别人,正是我自己。要我说,当我看到它运行起来的那一刻,我可比谁都开心——
话又说回来,既然你已经来到了这里,那么你一定想了解这个项目的前世今生,或者,你有想问我的问题,准备好,让我们暂时回到2012年的夏天……
原点
2012年6月,在一个早已被我淡忘的契机中,我误打误撞来到了百度贴吧fursuit吧。
映入眼帘的,多是从各处搬运来的兽装图集,一般是某位fursuiter的返图合集;此外还有不少搬运自YouTube的视频,比如EZ Wolf的《江南style》,或者Keenora的兽装蹦极。
我难以描述我第一次看到兽装的感觉,这是一种……我从未见识过的东西。很神奇,很微妙。
很迷人。
我想着,那么留下来吧。
我对这个前所未见的新事物很感兴趣,但同时又小心地保持着距离感。我没有立刻按下加入贴吧的按钮,只是隔几天回来看一下最新的帖子。
吧里流行的东西时刻发生变化。以我那么不频繁的上线机会,几乎每一次来,首页的画风都有不小的变化。
有一次,首页靠前的几个帖子都是“3D图”,其实就是在左右两边摆上相同的图片,然后用斗鸡眼看出3D效果。
但这时还在2012年,国内的第一套兽装全装要到2013年才出现。
我那时不知道furry,也没往动物的方面想。甚至,我在fursuit的世界混迹了好一阵子才意识到furry这个“上游”的存在。
时间来到2015年,国内举办了历史上的第一次兽展,“神州萌兽祭”。
在这个时间,我们已经有了好几套像样的兽装,基本都是自制。我们离脱离田园时期还远着呢。
但很可惜,那个夏天我正在为自己的Minecraft服务器合伙人跑路的事情焦头烂额,完全错过了这场值得铭记的大事件,以至于我对2015年的首次兽展没有太多印象。
事后想来,这实在是捡了芝麻,丢了西瓜。Minecraft从未给我除了游戏内容以外的快乐,开服务器实属自找不痛快,为什么不把精力放在能让人放松的事情上呢?
又一年过去了,此时是2016年。
那个盛夏,永远都会是我心中最经典的兽展,它叫“兽夏祭”。
至少在fursuit的世界,那个夏天是一场空前的狂欢——我们已经有了不少相当强悍的装师,有了全场手脚并用都数不过来的兽装。而兽展的欢乐气氛甚至传播到了人类世界,为这个在当时小众得不能再小众的圈子注入了大量新鲜血液——我们的人数,能以千为单位了。
而“兽装直播”的热潮,也正是从那时开始发迹。
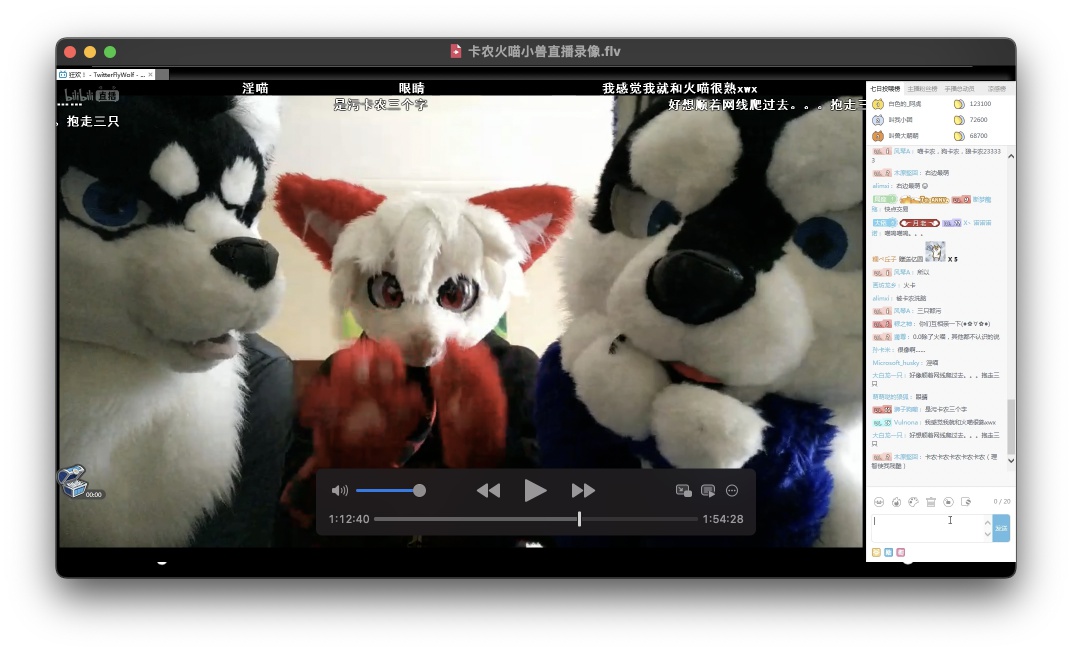
卡农现在的名字叫流银,小兽现在的名字叫艾尔,而火喵还是那个火喵。
度过了一个难忘的夏天之后,我们走向了2017年。
可惜,2017年的兽夏祭不尽如人意,可以称得上是毁誉参半。
但在此之外,更严重的危机正在酝酿着……
我们所知的历史即将迎来终结。
末日
正如你们已在档案馆主页看到的那样:
2017 年 6 月 19 日,吧主“混血狼狗”职位被百度撤销。
2017 年 6 月 20 日,用户“布偶新世界”宣称对原吧主意外下台的事故负责。
2017 年 6 月 23 日,fursuit 吧开始遭受爆吧。
……
2017 年 6 月至 2018 年 7 月,fursuit 吧间断遭受爆吧,时间跨度一年有余。
期间,吧主权力多次更迭,建吧早期的精品贴几乎被全部删除。
象征国内 fursuit 文化的亚历山大图书馆,在顷刻间被焚毁。我们的历史没有了。
2018年,在一整年的战火纷飞后,一切似乎已尘埃落定。原有的吧务团队被彻底清洗,取而代之的是“艾布”和“糊兔”,以及许许多多他们自己的手下。
他们不光清洗了吧主团队,还把他们的发帖,连同大量其他人的精品贴,尽数毁灭。
fursuit在国内的发展历程,一瞬间断了根。
故事的结局是,他们完全接管贴吧后,所有的爆吧机器人和偶装厂,在一夜之间全部消失了。
我后来才知道,在他们得手后的这三年里,后台的操作记录总共不到50条。其中30余条还只是清理之前的爆吧痕迹。
贴吧停摆了,这种发展完全停滞的状态持续了三年,就像小说中描述的那样,是”光明的中世纪“。
我不知道他们为什么要这么做。我很想质问他们,这么做对你们究竟有什么好处?你们想要偷取贴吧,那给你们便是,为什么要破坏文明,破坏历史?
你们费尽千辛万苦得到它,只是为了毁掉它吗?
“艾布”、“糊兔”、“软毛”、“LL”、”大召唤之门“,所有这些人的名字和身份全部交织在一起,拧成一团乱麻,我甚至不知道我到底应该找谁。
我不知道他们是谁,但他们是我最痛恨的一群人。
上部:曙光
2021年11月的一个午后,我做了个梦。
那是一个很大很大的剧院,关了灯,只有我站在聚光灯下。
这是一次兽展,但此刻看起来完全是苹果公司开发布会的样子。而我此时正站在蒂姆·库克该出现的位置上。
我面向面前黑压压的人群,举起了一张光盘。这就是我要发布的东西。
这张光盘里装有已经复原的,fursuit吧的完整副本,包括所有被艾布们毁灭的数据。
我把数据恢复了,就在这张光盘里,而现在我要把它给全世界看。
见鬼去吧,艾布。你们没能得手。
……
我醒了。
我醒了……
……
要是梦里的东西是真的,那该有多好。
多好啊……
要不,去看看吧。看看现在那里怎么样了。
那里没有吧主了。他们离开了。
而此时正有一个人正在尝试重新申请吧主,她叫“冰清”,一个我从来没见过的名字。
我自己的百度帐号在艾布们降临的那年就注销了,我没办法亲自上阵,如果冰清能成功拿下吧主,找她帮忙就成了唯一可行的路。
几天之后,冰清如期成为了新吧主。
那么,轮到我登上历史舞台咯。
我要改写历史。
下部:Creatio ex nihilo(无中生有)
有希望了,有希望了。
我开始头脑风暴,思考我能做什么。
是直接恢复,还是搞得更大一些, 比如做个赛博遗址公园什么的?
不过在此之前,我得先弄清楚当年到底发生了什么。我得去找她,让她把我捞成小吧主,我只有亲自看到后台历史记录才能明确接下来的动作。
冰清很快就答应了我。非常感谢她,能给予我一个陌生人这么大的信任。
但当我真正看到后台的那一刻,我还是愣住了。
在此之前,我已经猜测过好几种可能的情况,但实际发生的仍然完全超出了我的想象。
“play月光如水k”,他是谁?破坏都是这个帐号做的,这个帐号删除了几乎所有精品贴。
而我根本不知道有这号人存在过,我从来没在贴吧里见过这个人,无论是帖子里还是吧务名单。
更糟的是,这个号已经注销帐号,我也查不出他的任何过去。
和“play月光如水k”一起注销跑路的还有“飛翔之龍”和“大召唤之门”等好几个人,比这更蹊跷的,是当年“糊兔”的帐号现在变成了“艾布”的名字,对此我想不出任何合理的解释。
算了,别浪费时间在复盘这些抽象人的行径上了,现在只有一件事情重要,那就是数据的完整性。
我联系上了我的好几个高技术力的伙伴,在经过又一番头脑风暴(尽管多数时候完全是我自己在对着空气讲话)以及好几次推翻计划后,我最终明确了我要做的东西:
一个可以回溯贴吧历史上任意一刻的“时间机器”。
它的代号叫Project Ex Nihilo。
“无中生有计划”。
我根本不知道我有多大把握,但我得试试,我要把数据恢复得尽可能完整。
以及……我要把我现在做的事情都记录下来。我不能再让更多的东西被遗忘了。
六个月后
https://fursuit.catme0w.org 正式上线了。
这是孤独的行为艺术吗?我不知道,也许我可以因此一炮而红,也许不会,只是独属于我一个人的感动。
但至少,我看到了我想看的东西。
关于我开发这个项目的心路历程,真的有太多可以说的了。
从开发的第一天起,我就时常会把我自己的感想写下来。这些原本是用作参考和内部分享,但现在我打算把它们原封不动地给你们看。
与其在这里重新回忆和转述一遍当时的灵感,或许直接让你看到我当时每一天的想法、见闻和进展,要更真实,更震撼些。
如果你已经看到这里,非常感谢你的陪伴,接下来请一定一定要点进去看,这全是我心血的结晶。
那么,祝阅读愉快。
(包含较多的技术内容,对于没有相关知识的读者可能略显难懂。)
尾声
如果你去查询我的域名 catme0w.org 的证书签发历史,你会留意到在2017年中旬,时间机器的域名 https://fursuit.catme0w.org/ 就已经出现过了。
当时贴吧刚被偷家,另起炉灶是当时主流的声音之一。
不少人想以此为机会创建论坛,进行数字大迁徙。
我也不例外。
可惜,我很确定直到今天也没人再建立起成规模的论坛。
不过我最终还是在这同一个域名上,看到了我想看的东西。
如果你已经读完了我的研究笔记,你可能会疑惑为什么笔记在3月就戛然而止了。
这一点倒是没有什么太多神秘的原因,单纯是因为我太懒,以及编写“贴吧模拟器”不少时候像是体力活,例如微调界面样式等等。
然而六月正式发布的版本其实远远未达到原定设计中的预期,它仍然是一个半成品。
我后来去忙一些自己的事情了,反正这个版本暂且能用,就先放着了。
转眼到了九月,对creatio(时间机器前端程序的项目名字)来说,新的危机出现了。
The story behind the scene of this website is truly epic, but it is still far from finished. After about June last year, I noticed there was a critical SEO failure and it eventually wiped all of itself from Google search results, and the only way to fix is a big overhaul.
One of my friend joined the development, but we immediately ran into a trouble. Something really, really bad happened, caused the overhauled version indefinitely postponed.
I am never a good programmer. You can see through the source code of the original version, but also the only version available: https://github.com/CatMe0w/creatio
I’m also not a talented one. Under the hood of this “megastructure” is shittily shitty shitcodes. And that leads to the final collapse - not the collapse of the project, but -
me.
https://twitter.com/XCatMe0w/status/1651291197112193027
https://twitter.com/XCatMe0w/status/1651291197112193027
不过,这是另一个故事了。
尾声之后:希望
https://www.youtube.com/watch?v=BxV14h0kFs0
《这个视频有58,394,109次观看》(This Video Has 58,394,109 Views)
作者 Tom Scott
“计算机历史博物馆里中的软件和硬件,有些在我成长的过程中贯穿始终,我很怀念这些东西,因为它们能自己保持运行,它们不需要来自公司的持续维护。
但是如果你所做的东西依赖于其他公司的服务,那么……存档就会变得非常非常困难。
每隔几分钟,我的代码就会在YouTube查询这个视频有多少播放量,然后更新视频标题。
也许在你看这个视频的时候它还在工作。
但最终,它会停摆的。
YouTube也会如此。
一切都会如此。
熵,逐渐下降到无序状态,这是宇宙的基本规律之一…
……熵,最终会把我们全部毁灭。
这就是我选择在这里拍摄的原因。
多佛白崖是英国的象征,是这道雄伟的屏障,但它们,本质上只是石头而已。
时间和潮水会把它们冲走,在很久很久以后。
这个视频,也会消亡。
但这并不意味着你不该创造。
尽管最终会消亡,并不代表不能产生影响——延续到未来的影响。
快乐。奇迹。笑声。希望。
世界可以因为你在过去创造的东西而变得更好。
虽然我确实认为,人类的长期目标,应该是找到击败熵的方法,但我很确定现在还没有人知道该从哪里开始解决这个问题。
所以,在此之前,请尽量保证你所做的事情能推动我们朝着正确的方向发展。
它们也许不是很庞大的项目,甚至,也许只有一个观众。
即使不能永恒存在,也要努力让它们留下一些积极的痕迹。
是的,在将来某天,更新这个视频标题的代码会失效。
也许我会修好它。
也许不会。
但那段代码,从来都不重要。”
鸣谢
感谢为我提供帮助的项目(尽管我完全没有使用它们的代码),以及伴随我一路走来的朋友们。
排名不分先后。
可能有遗漏。
项目
https://github.com/Starry-OvO/aiotieba
https://github.com/52fisher/TiebaPublicBackstage
https://github.com/cnwangjihe/TiebaBackup
https://github.com/Aqua-Dream/Tieba_Spider
朋友们
Aster
mochaaP
LEORchn
ShellWen
NavigatorKepler
为此项目编写的 GitHub 仓库
https://github.com/CatMe0w/fursuit.catme0w.org
https://github.com/CatMe0w/ex_nihilo_vault
https://github.com/CatMe0w/backstage_uncover
https://github.com/CatMe0w/proma
https://github.com/CatMe0w/rewinder_rollwinder
https://github.com/CatMe0w/proma_takeout
附录:Project Ex Nihilo路线图
前期,数据提取准备:
取得贴吧后台日志,确认修复的可行性和数据完整性
- 数据修复可行,但似乎没有办法在不恢复帖子的情况下,直接通过后台导出完整的帖子内容。
编写后台日志导出工具“uncover“
导出全部后台日志到sqlite数据库中,同时保留一份原始html
这部分在本地进行,数据无需公开。
(下载 uncover.db.xz)
根据前一步导出的数据库,统计总共需要恢复和再次删除的帖子
- 后期的爆吧机器几乎无法与真人帖子区分开,简单地说朴素贝叶斯肯定行不通,若人工分析的话工作量过大(甚至人工也无法区分),同时为了保证项目的中立性,计划直接恢复后台日志中所有被删除的帖子,不区分真人或爆吧。
恢复的顺序:时间顺序,由近向远
删除的顺序:由远向近
重新编写爬取所有贴吧公开帖子的工具”proma“
原定计划为基于Aqua-Dream/Tieba_Spider魔改,但由于过于容易撞到反爬,
并且无法保留完整原始数据,以及这一项目没有开源协议,还有魔改工作量过大,因此计划变为完全重写。计划使用selenium,单线程,或grid+多job运行,保存为warc存档格式。草案:将处理html并输入sqlite的部分解耦,之后编写后续工具,直接使用warc档案作为数据源,不使用百度的线上服务。- 除Aqua-Dream/Tieba_Spider的全部功能外,还需要另外实现的部分:
- 草案:使用cnwangjihe/TiebaBackup中的手机端api取代电脑版网页+html parser
- sqlite替代mysql
- 接入代理池
- 爬取签名档
- 爬取昵称
- 爬取头像
- 可选:爬取红字或加粗格式
取得一个大吧主的BDUSS,供批量恢复和删除帖子- 小吧主没有恢复帖子的能力,
这是唯一的办法了。 - 格局打开中,详见1月10日研究笔记
- 小吧主没有恢复帖子的能力,
在大吧主BDUSS的帮助下,编写自动化恢复和删除帖子的工具”rewinder-rollwinder“
这个工具的编写需要大吧主的BDUSS,用于找到与恢复相关的接口。- rewinder:恢复被删除的帖子
- rollwinder:rollback the rewinder
中期,数据采集之夜:
(行动名称:决胜时刻,The Showdown)
- 开动rewinder,恢复历史中所有被删除的帖子
- 这部分可以在本地运行。
- 爬取并公开所有帖子
- 这部分将使用GitHub Actions运行,爬取的数据将直接上传releases(附带sha256sum),确保整个流程不存在人为干涉。
- 把所有帖子送入Wayback Machine
- 确认数据有效后,开动rollwinder,批量删除这些帖子(回滚rewinder的全部操作)
- 这部分可以在本地运行。
- 导出并公开后台日志
- 这部分也将使用actions运行,数据也是直接上传到releases,这部分数据将作为日后其他环节的基准数据集。
后期,数据处理与展示:
- 给项目想个好听的名字
- 撰写静态主页的文案
- 编写静态主页的前端界面
草案:鉴于我根本不懂设计,比起自己糊一个观感并不算好的主页,考虑使用HTML5UP或Carrd等模板进行魔改。- 还是要自己画界面
- 编写时间机器的前端界面
- 编写时间机器的后端接口
- 用于读取uncover和proma的数据集,以json格式呈现给时间机器前端。
若使用cloudflare workers,编写关系型数据库转换为workers kv的工具。- kv是大便,得找个东西存sqlite数据库
后期前后端开发todo list
前端
- 主页内容
- 下载页内容
- 搜索框
- 可互动的评论组件
- 视频播放器
- 查看器footer
- 吧务后台设置项
- 语音播放器
后端
- 脑回路正常的搜索实现
- 重写并上云
尾声,正式上线与后续项目:
- 想个好一点,能吸睛的宣传文案,在空间等地方发布
- 若项目成功,考虑开启后续项目:群星计划
- 一个供用户提交和存档已绝迹福瑞内容的平台,人工审核,以torrent等方式分发,不破解付费墙。
纯开脑洞部分:
- 将所有的数据集和原始
warc档案刻录在M DISC等适合长期存储的介质,搞个什么collector’s edition(? - 给项目画个福瑞吉祥物(??
附录:研究笔记
2021年11月29日
突发奇想,回到fursuit吧看看,我原本以为那里还是一片废墟。一回去可不要紧,我说对了一半,确实还是一片废墟,但是吧主没有了。他们离开了,或者说是被百度弄下去了。
等了三年,终于有希望了?
11月30日
百度贴吧的后台是可以恢复被大小吧主删除的帖子的。混血狼狗在fursuit吧几乎所有的发言被剿灭,我不太相信这是百度做的。若是百度所为,应该直接让他的号完全不能被查看才对。
当下,有一个人,不属于他们的一位,正在申请吧主。我手头没有像样的百度账号了,仅剩的两个一条发言都没有,这样的号申吧主肯定没指望,不然我肯定要插一手。
那么,如果那个人能搞到吧主,或许能找到他,帮我们重新导出历史数据。这样或许能建立一个赛博圆明园遗址公园什么的,象征2011-2016这段国内fursuit文化的田园时代。
12月4日
他上了。目前他也是fursuit吧和兽装吧唯一的大吧主。
修订:应为“她”。下同。
我联系到他了,我正在问他能不能把我捞成小吧,然后我可以亲自接入后台,考证那些数据是否有修复的可能。
我考虑过更温和,更不引人注目的处理方式,但我实在想象不出当年到底发生了什么,可能实际发生的事情远超我的想象力。无论如何,在一切都是未知的情况下,思考皆是空想,一切只有在接入后台之后才能做下一步判断。
我希望尽可能不改变当前贴吧的状态,只把数据复制一份,自己建立一个不受百度控制的赛博遗址公园。
成为小吧的话,我应该可以提取所有数据,再不济也能提取一个标题。只是数据清洗一定很麻烦,毕竟爆吧的记录应该不少。
接下来我准备买个域名,开个网站来存放数据,打包的数据就用torrent分发,现在我要写一下文案了。
这就是艾斯吧的操作,我们就要做到了!
(“艾斯吧的复仇巨瓜,吃笑了所有人” https://zhuanlan.zhihu.com/p/159644849)
12月6日
我上了。
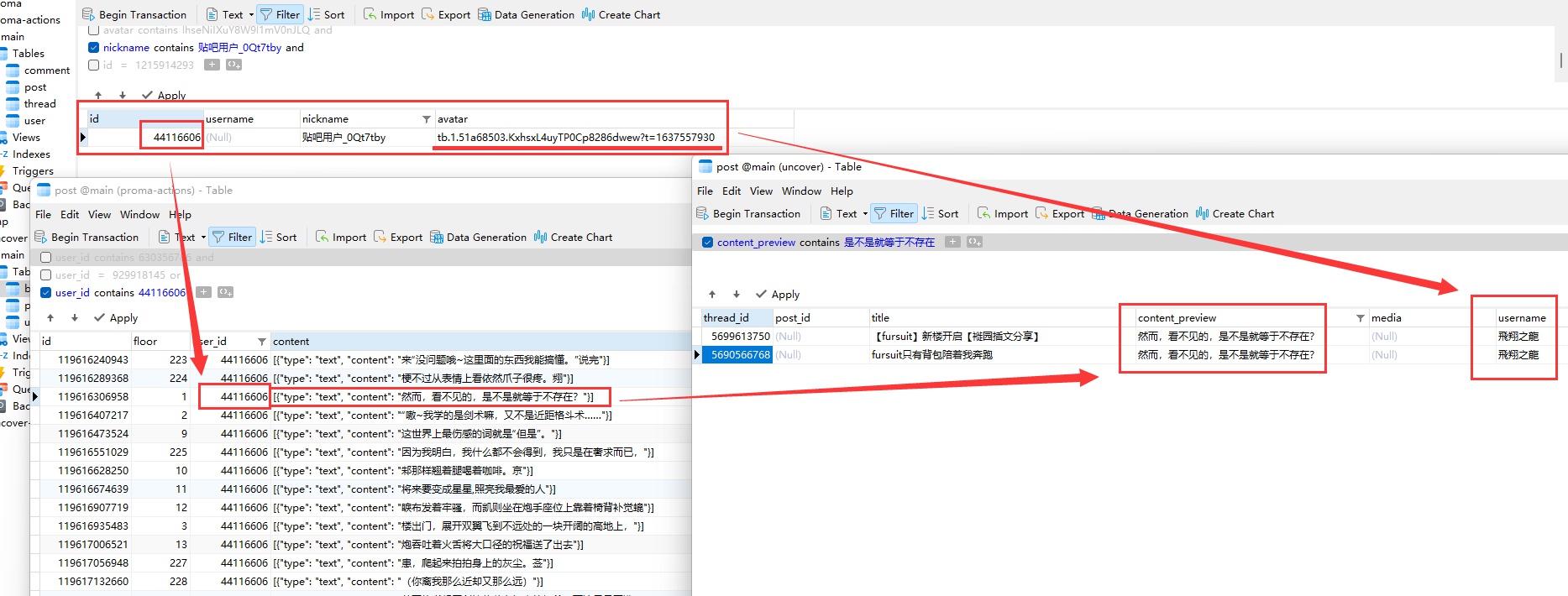
我的所有猜想都被证实了。后台呈现出的景象一言难尽,几乎可以用光怪陆离来形容。狼狗在田园时代搬运的帖子的确被全灭,操作人是一个叫“play月光如水k”的账号。我从未见过这个账号。他是谁?
包括“play月光如水k”在内,“飛翔之龍”和“大召唤之门”等几个账号都已不复存在。他们注销账号了。还有更蹊跷的事情:2018年间,“糊狸狐兔”的百度账号现在变成了“AbramsDragon”的名字,这一点我找不出任何合理的解释。
我还是不要再浪费时间尝试复盘2018年间的大乱斗了,即使弄清楚了又如何呢,不过是再掀起一次撕逼的狂潮罢了,没法解决任何问题。
只有一件事情值得关注,那就是数据,数据的完整性。
12月7日
我花了三个小时部署好这个软件,php和url重写真的是烦死人了,一想到过去的程序员和运维需要和这些东西打交道,就庆幸自己真是生在了一个好时代。
https://catme0w.org/ekr3ceijfeac6e2iyjt4d7f4/
这个东西可以把贴吧的后台投射到公共互联网,这样我就可以让一些其他人页看到当年真实发生的事了。当然,我还不确定要发给谁。
说实话,我不太希望过去的贴吧领导班组介入这件事,否则可能会影响(舆论上的)中立性。整个工程在舆论上的地位是非常重要的,毕竟明眼人都能从后台日志看出发生了什么,我必须在舆论上立于不败之地才行,不能有任何风险。虽然,要说这世上对此最应该有知情权的人是谁,也只能是这几位亲历过这事的老人们了。
这个程序只是个临时界面,之后要如何收集、修复和整理数据,恐怕是个难题。
首当其冲的是,我们从贴吧后台看到的已删除的帖子,如果是主题帖,只能看到一楼的头几个字,其余的部分完全不可见。要访问这些记录,必须恢复整个帖子,那么这就不可避免地会修改现在的贴吧。
如果放远一点,假设我们用这种方式去查看所有被删除的帖子,就意味着我们需要把它们全部恢复。这对于贴吧绝对算是另一种程度的毁灭性打击了。
当然还有一种方式,就是恢复所有帖子,爬下来之后,再把原本被删除的帖子重新删一遍。
这种方法的缺陷也显而易见:首先是所有被删过帖的人,他们的“系统消息”会被我们轮一遍;更严重的是,如此操作会让贴吧后台日志变得面目全非。最大的问题是,在这么一通现实重构般的操作后,我们如何保证整个贴吧真正恢复到“我们来之前的原样”——简单地说,如此一来,我们在舆论上会占下风。
于是,现在最主要的问题就是,急需找到一种不恢复帖子就能获取被删除帖子完整内容的方法。
然后是不那么严重的问题:我们要建立什么样的档案馆。
现在,假设我们已经能够导出贴吧的被删除帖子的完整内容,不管是使用什么方式。我原来的想法是,只建立一个2016年左右的“快照”——即在那个时间点的贴吧状态。但是我亲自接入后台后,发现这其实很难:如果要精确还原到2016年的状态,就必须分析贴吧后台的所有日志;单独回退某个人的全部操作,得出的结果是不准确的。
那么我们不妨直接实现一个更远大的目标:将当前贴吧状态和所有的后台记录结合在一起,制造一个可以回溯任意一刻历史状态的“时间机器”。
于是,这样会引出一个新的问题:在我们创造时间机器之后,将来新出现的帖子和操作怎么办?我们已经暴露了贴吧过去的一切,包括每个吧主的每一次操作。
简单地说,我们会让贴吧失去将来的存在价值。
为了解决上述问题,我考虑了一个不那么激进的方案:
假设我们最终没能找到不恢复帖子来提取完整内容的方式,那么我们只能通过完全回退某几个删帖机的行为,来恢复一些最有价值的帖子,这其中大多是混血狼狗的。
然而,接下来,我们所做的一切将陷入一个极度尴尬的状态:既然贴吧已经恢复了,为什么还要舍近求远,去观看民间的备份呢?
对于我们来说当然不是这样,我们深知百度的无底线,备份是必须要做的;但是大多数人认识不到这一点,或者尽管能意识到,但是光是访问速度和易用性上的差异就能让大多数人放弃了。
现在很可能无法找到完美的方案了,做出取舍恐怕无法避免。
比起这个,还有一个更要紧的问题:必须尽快再扶持两位大吧主上任。
目前对方近期仍在兽人吧活动,放弃fursuit吧很有可能只是一个意外。按过往经验推断,只有一个大吧主的兽向贴吧非常容易被举报掉。我本来是不想自己上大吧的,但是考虑到可能要进行大规模的帖子恢复操作,可能还得我自己上。
那么,还得再找一个人,甚至还得准备好几个替补。
下一步:将当前状态的贴吧后台和所有公开可见贴吧内容进行完整提取。尽管具体方向仍不完全明确,有些事情是可以先做起来了。
正好是因为代码古老,百度贴吧的前端几乎没有使用js,这意味着我不需要使用selenium。只要requests下载html,然后喂给html parser,就可以产生出我们需要的数据结构了。
12月8日
https://github.com/CatMe0w/backstage_uncover
导出后台日志的程序原型已经做起来了。昨天和一位技术顾问聊了一下,计划采用sqlite存储。
其实我一开始根本没往数据库的方面想,经他一点我才意识到问题。我本来打算随便搞个json存一下就算了,但是数据量可能会非常庞大——数十万行对于sqlite来说只是基本操作,但数十万行的json就吃瘪了,这还不算query的耗时差距。
我正考虑在程序完善后,让github actions来运行并导出数据。主要还是舆论方面的考量。因为说实在的,后台记录中的东西实在是太……难以置信了。丑话我就不多说了,意思到了就行。
让actions运行,就是让actions运行那一刻仓库里的程序,爬完数据后直接上传到releases,再附上sha256sum,确保从代码到运行环境,再到最终的发布流程中,没有任何一个环节可以人为干涉和篡改数据。
贴吧后台的HTML也属实一言难尽。HTML结构倒是还算规整,但有一些数据总是缺斤少两,或是本身就呈现得乱七八糟。例如有一些<li>的文本前后带五六十个空格,或者是发帖日期没有提供年份等等。
年份的问题,一开始我们打算爬一下对应帖子前后的帖子,通过临近的帖子来算出年份,但是很明显这样鲁棒性(robustness)不佳,爬多了还有可能撞反爬。
Aqua-Dream/Tieba_Spider的贴吧爬虫似乎相当符合我们之后爬公开贴吧的需求。主要的缺点就是它使用mysql而非sqlite。我们不需要mysql。
我试着跑了一下这个程序,情况比我们想象中的严峻:目前的贴吧共有34页,如果把被删除的帖子全部放出来,这个数量还得再扩充一倍;而这个程序在爬到最多不超过29页时,就会被反爬验证码拦下来。
对于我的本地环境来说,这倒是很好解决,接入我的梯子,梯子给个负载均衡就行。但是对于actions,情况就棘手很多了。看了一下相关issues,最合理的解决方法应该是魔改代码,接入一个公开代理池。
结合了技术顾问的一些建议,基本上确认接下来的操作路线了。
目前操作日志的总数是5126,其中“删帖”占了4291条。
找一个夜深人静的时候,将所有删除的帖子全部恢复。完成之后,完整爬取整个贴吧,最后将恢复的帖子删回去。从外面看上去就是无事发生,除了有些用户的“帖子被删除提醒”可能会被轰炸一下。
这个方法的确有一些离谱,但是在百度极为糟糕的管理制度和程序水平之下,这应该是最好的方法了。
最后的最后,将后台的操作日志再爬一份出来,合并两个数据集,基本上就是贴吧有史以来的完整记录了(除了被百度删除的,那些吧主也看不到,任何人都看不到)。
把所有数据拿到手之后,这一阶段就算完成了,之后的工作就完全与百度的服务无关了。
12月9日
另一位顾问提议我保存warc档案。
warc是一种类似mhtml的格式,可以最大限度地保存一个网页加载的过程和数据。同时,有了warc,甚至将来还能上传到wayback machine(在确保整个爬取流程可信的情况下,即前文中提到的actions运行)。
但问题是,Tieba_Spider不使用浏览器,根本不可能保存可供重放的warc。Tieba_Spider做的事情只是单纯下载html,抽出特定文本,然后输入数据库。
如果需要warc,我需要重写整个工具。
我想到了一个精妙,但其实做起来非常弱智的方法来判断发帖年份:找到全贴吧每年第一个帖子,把他们的id硬编码到我的代码里,这样就可以在不发起任何额外网络请求的条件下精确判断年份了。
若是使用人力二分法,寻找这些帖子应该很快,但实际上这个过程花费了我超过一个小时的时间。因为我在手工遍历的过程中,发现全贴吧至少有90%的帖子都消失了。
具体来说。是90%的id是空的。其中大多数是被删除,少部分“账号被隐藏”,少部分是空白错误,还有一个“贴吧被合并”。
所以我们损失了90%的过去。
12月10日
我在修uncover剩下的bug时逐渐被气出脑溢血。
我发现了一批在2019年发帖的ip匿名用户。2019年哪来的匿名用户?我到底要为贴吧这个垃圾产品补充多少的edge case处理?
Tieba_Spider还有别的问题。它不能爬取昵称,而如果只使用用户名,无疑是很不妥当的,很多人改昵称就是为了不再顶着一个黑历史般的用户名。
贴吧的网页版不是前后端分离架构,若使用电脑版进行爬取,需要处理html。有一个使用手机端api的爬虫,但功能与我们的需求不完全重合:cnwangjihe/TiebaBackup
使用手机端api,或许能够规避反爬……?
答曰,不能。手机端api同样会撞上那个傻子旋转验证码。技术顾问想要正面迎战这个验证码,找一个自动化识别它的方式,但我其实主张绕过它,用代理池或者selenium。
这个项目的所有代码必须保持最简单最直接的设计,尤其是坚决不能炫技,炫技必然引入复杂性,一复杂,不稳定的概率就大了。
传来噩耗:现在的百度贴吧,只能申请一个大吧主了。这个公司为了流量真是无所不用其极。
去找现在的那位大吧主成了唯一的路,只能期待他愿意帮助我了。
12月11日
稍微展望了一下将来的计划,在数据库准备好之后,网站就要上线了。
静态前端计划使用cloudflare workers,数据库后端也用workers。不过问题来了,workers数据持久化的方案叫kv,这是个令人血压上升的东西。简单地说,kv就是个python字典,然后这玩意还有容量限制,每个条目不能超过100 MB。
所以,直接塞数据库不行,转换成kv的格式也不行,只能另谋高就。我实在不想和服务器打交道,workers还便宜得多,操作得当甚至一分钱都不要。
workers官方钦定了几个第三方数据库服务,而其中的prisma正好就支持sqlite。不过不知道prisma的费用怎么样,按理来说十万出头的行数应该只算是洒洒水。
好像prisma完全不是我理解的这个意思,我寻思还是给cloudflare交钱吧。反正无论怎样都比自己买服务器要便宜了,主要是还不用管运维。
尝试用webrecorder的pywb存档了几页贴吧的原始数据,warc格式。
问题相当多……首当其冲的是数据量,爬了两三个带图的帖子之后,即便是gzip压缩过的数据量也达到了115 MB。若是爬取整个贴吧,这个规模要上传releases,恐怕是相当不利。
其次是pywb的网页代理难以处理贴吧的一些js,有些控件和按钮会失灵。
最后是我觉得最麻烦的一点,贴吧的广告数量巨大,还时不时弹窗要求登录账号。我平时开着广告屏蔽插件,对此一无所知。到时候可是无人值守运行的无头selenium,要送个广告屏蔽插件进去,还要在正式爬取之前加入chinalist(针对国内广告的屏蔽列表),谈何容易。
我有点黔驴技穷。
12月12日
uncover已经完工,在经过几轮测试后,可以视作GA(generally available,普遍可用)。
值得一提的是,贴吧后台似乎没有像公开贴吧那样有着严格的反爬,但偶尔还是会出现timeout。
爬取公开贴吧仍然没有什么进展。或许现在将重心转向前端界面或者文案会更合适?
12月13日
项目的进展速度确实放缓了。今天几乎是原地踏步。
想起之前有一位顾问提过,自己在真实浏览器上用js爬了100页也没撞上过反爬。我询问了一些当时操作的细节,他表示针对我的这个需求要重新测试一遍才能知分晓。
静候他的佳音,这两天专注公众能看到的部分了。
12月14日
有人提议考虑放弃warc格式,但是有一位坚持要求保存所有原始网页到Internet Archive Wayback Machine,那么就没办法放弃warc了。
Wayback Machine对百度贴吧特别不亲和,例如在2016还是2017年至今Wayback Machine自行爬取到的贴吧全部是绿气泡30x redirect,事实上没有保存到任何内容,诸如此类。
因此,我们自行保存warc再借助Internet Archive认证的团队上传成了唯一可行的途径。
12月16日
在几个顾问的讨论之下(由我作为沟通的桥梁),还有拉上Archive Team的IRC一块,终于算是明确了warc格式相关的路线,那就是——
放弃warc。
具体来说,是放弃由我们亲自用浏览器爬取和保存warc。
过去数天,我们几人针对百度贴吧网页在浏览器和各类archiver中的行为各自做了研究和观察,我们意识到,“在warc档案中完美保存所有数据”可能根本不具可行性,就算有,开发也是极为棘手的。
除了上文中已经提到的广告问题,最大的问题是登录墙。登录墙最直观的体现,就是在楼中楼的回复当中。
假设一个帖子中的楼中楼有大于等于11个回复,此时楼中楼会分出两页或更多,每页最多显示10个回复;没有用户操作的情况下显示前5条,用户点击“展开”可以看到第一页的全部10条。而登录墙的行为是这样的:不登录账号时,只能看到前5条,点击“展开”会弹出登录提示;登录账号后则没有任何限制,可以任意查看。
在网页内部逻辑上,楼中楼的组件渲染直到用户滚动到对应的楼层才会开始,但这一过程并不依赖网络连接。实际上,在打开帖子的一刻,会向(贴吧主站域名)/p/totalComment发送一个xhr,返回值为当前页中,每一个楼中楼的前10条(第一页)内容,json格式,但并不包含第二页及之后。楼中楼第二页的加载是单独的xhr,返回值是一堆html,也就是第二页的html。
对应到我们的各种archiver和crawler中,情况大致如此:不登录账号,楼中楼只能看头5条;客户端带个油猴user script破解掉登录墙,最多可以看10条。
当然,的确可以想办法送个登录态进去,用我的账号或者谁的账号也好。但这样爬出来的内容,显然已经很不适合上传到wayback machine——试想一下,在wayback machine的存档中,看到顶栏一个用户名,侧栏一个用户名,还有这个用户的一堆消息通知之类,怎么看都离谱。
更重要的是,这在技术上难度颇高。首先,我们要怎么送登录态进程序里?如果用wayback machine api(如果有),我甚至不确定是否可行;如果是我们自己运行的程序,比如browsertrix crawler或者手工pywb,要怎么把一堆cookie弄到actions里?硬编码到代码里吗?别忘了,这部分程序是要让actions运行的,不然没办法证明爬取流程可信。
这还没完,程序操纵浏览器加载完网页后,还得滚动下去,还得处理html,去挨个点击那些“展开”和“翻页”按钮。卧槽,光这么一说我都感觉这复杂程度是空前的大。更何况,要实现这个功能,browsertrix crawler这种高度自动化的方案肯定不好使了,pywb+puppeteer或pywb+selenium,选一个吧……
不行了,不行了,这一复盘才发现我们原来想做的是如何一个巨坑。
假设我们真的完成了以上的一切,会发现一个超级惊喜——投入和产出完全不成正比。
有楼中楼的帖子有多少?超过5条和需要翻页的楼中楼有多少?这个数字绝对不会大。与实现难度相比,放弃才是更好的选择。更何况,wayback machine自身已经可以存档除了这些楼中楼以外的全部数据,我们的确不需要亲历亲为。
我们真的无法兼顾一切且做到完美,取舍是必要的。
P.S:之前在遇到广告那个难题时我曾考虑过,是否可以在后期人为抹掉广告div。显然,这个想法在我的脑中只存在了三秒不到——被人为处理过的存档,不是原汁原味的存档,也就失去了存档的价值。
那么,可不可以只存warc供我们自己用,不上传wayback machine?这个想法只比上面那个多活了两秒。毕竟,在有了自研™时间机器的情况下,不会有人愿意重放和翻阅那一堆warc文件的。
P.P.S:上一条研究笔记提到的绿气泡,其实是贴吧的目录(吧主页)。经过测试,帖子可以正常爬取,这就足够了。
2022年1月10日
- 上篇
有一阵子没更新了,但其实我没闲着,一直在挤牙膏式更新proma。
但说实话,你从我这个状态都能看出来了。我不想写proma。
在移动端接口的加持下,proma的开发难度已经降低了非常多,只是唯独有一个部分,是移动端接口力所不能及的。
简单地说,移动端接口爬出来的楼层正文,会吞掉空行。比如两个段落间空了一行或者很多行,在移动端接口里是看不到的,两个段落会紧紧贴在一起,这其实也是手机app的行为。
这非常丑陋,更重要的是,有信息的损失。而这种损失本不应该发生,因此必须想办法修复它。
我的想法是,先用移动端接口爬楼层,入库,再用网页端把所有帖子爬一遍,替换所有正文为有正确空行的版本,顺带补充上签名档。
爬移动端的部分相当简单,甚至可以说是一种享受(相比于处理贴吧的HTML)。数据源是规矩的JSON,虽然存在着命名混乱和夹杂大量多余数据之类的毛病,但瑕不掩瑜,比处理HTML舒服多了。
但毕竟最后还得和HTML打交道。说实话,这部分我是真的不愿意写,更何况也一筹莫展。过去这么多天了,我也没想到实现它的合理路线,其实倒不如说,我实在是太讨厌百度的HTML了。
然后是一个我最近才意识到的巨大隐患——我认为吧主不太可能会把他自己的BDUSS就这样拱手让人。因为,我现在才意识到,BDUSS不是专门给贴吧的一个token,而是所有百度产品。
例如,百度网盘。
如果是我,打死都不可能把BDUSS给别人,更何况是给一个并不算很熟悉的网友。
然后我就想,虽然之前在Google上找不到别人公开的恢复帖子的接口,但或许可以去GitHub找找看?只要我们能找到接口,就能做出rewinder。之后,只要把成品rewinder给吧主运行就可以了,不需要让BDUSS离开他的电脑。
还就真让我找到了——
而接下来,我们或许迎来了整个项目立项以来,第一个好消息。
- 下篇
这就是那个有恢复帖子接口的代码,这个接口我找了很长时间,本来以为必须要亲自拿到大吧主的BDUSS去找,现在居然不需要了。
然而,比起接下来要发生的,找到恢复帖子接口这个宝藏,居然显得有些平平无奇。
惊喜在这个repo的README中。
摘录:
“以客户端版api为基础开发,这意味着小吧也可以封十天、拒绝申诉、解封和恢复删帖(需要大吧主分配权限)。”
如果他没骗我,这意味着我不再需要找什么大吧主的BDUSS,也不需要在整个流程无法调试无法测试的情况下,把程序给大吧主去运行了。
我可以完成一切了。
我看到这行字的时候,真的差点要哭出来了。一个多月了,我们可曾遇到过什么好消息?但今天,我们终于有了一个惊喜,一个奇迹。
当然,也有一件事让我感到微微不快,就是我在他的代码中找到了通过移动端接口爬帖子目录的方法。
遵循一个基本定理:贴吧的移动端接口总比网页端好处理。我做了好长时间的网页端爬帖子目录,肯定是要废弃的了。但必须废弃啊,移动端接口的鲁棒性比我那爬网页的草皮架子好多了。
就是好几天白干了,有点不爽。
接下来要做的,就是确认一下他到底有没有骗我,小吧到底能不能恢复删帖了。
修订:没有冒犯Starry-OvO前辈的意思!只是这边最开始是不公开的笔记,所以比较口无遮拦一点。
1月24日
很遗憾我没能找到小吧恢复删帖的方法,但是Tieba-Cloud-Review的作者用户页内留下了唯一一个联系方式:邮件。我尝试通过这个邮件与作者取得联系,但是已经过去快两个星期了,杳无音讯。不过有他代码里接口的加持,rewinder应该能够直接使用,到时候,把程序交给大吧主就行了。
尽管前期工作的容错性还是低到极限了,但至少不是彻底没有出路。
此外,通过移动端接口获取帖子目录的方法不可行,存在只有移动端不可见的帖子,而这类帖子的比例在前两页中甚至超过5%,原因不明。
雪风丢给了我一堆当年部分精品贴的本地存档,2018年产,是那种浏览器里直接按Ctrl+S保存下来的“标题.html”加上“标题_files”的形式。其实数据量比我想象中要少。可以拿来给前期工作的几个程序做测试,而且和我之后的路线并不冲突。
之后大概会做成torrent,和我的数据一起分发。
我花了数天编写修复正文空行的算法,算法很复杂,推翻重做了好几次,但仍然只能满足几个(尽管是多数)情况下的特例,鲁棒性其实非常差。
意思就是,它暂且能用,但我完全不放心让它到生产环境上去运行。
与其同时还还有新的问题:红字和加粗。之前一直忘了这俩东西。
但是对于目前的修复算法和程序逻辑,如何修复加粗红字,可谓彻底走入穷途末路了。
此时有人点醒我,他大概是这么说的:如果是他做,他会直接把网页端的HTML原样入库。
我:陷入沉思
他说的确实有道理,如果直接用HTML入库,就不再需要做任何复杂的修复。即便是有百度的垃圾数据夹在其中,也可以很容易地剔除,或是在之后我的网页上实时修复。
这意味着,“proma”这个前期工作的数据采集部分,将立刻成熟;前期工作将立刻结束,后期的网页与后端工作很快就能开展。
为什么我会陷入沉思呢,因为如果这样切换路线,将有近一半的已有代码要被废弃。
但是为了获得尽可能好的数据,割肉不可避免。
1月29日
2022-01-29 01:50:57,518 [INFO] Current page: posts, thread_id 7648701681, page 1
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_top" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_01.png);height:17px;"></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_middle" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_02.png)"><div class="post_bubble_middle_inner">加油</div></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_bottom" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_03.png);height:118px;"></div>
elif item.get('class') == ['post_bubble_top']:
return None
# 直接放弃使用了奇怪气泡的帖子
# 这个项目的复杂程度早已远超我的预料,若按计划,项目的规模绝不应该膨胀到现在这个状况
# 随着需要专门处理的edge case不断增多,程序的鲁棒性也肉眼可见地暴跌
# 使用了奇怪气泡的帖子大多都是回复,而且往往没有复杂的格式,再加上它们的数量非常少
# 所以,对于这类帖子,直接保留原来数据库中的content吧
1月31日
嗨,新年快乐。今天,proma已经正式GA。
这比我预期来得迟,但和项目现在的复杂程度相比,倒也算合理了。更何况正好在新年的日子,也算讨个口彩了。
前期工作已接近尾声,接下来要做的,就是检查前期项目剩余的bug,进行多次全量测试,确保运行的稳定性。
一切完成之后,就可以送proma和uncover去GitHub actions了。
2月5日
proma的现有代码已经完善,除非需要大改,应该不剩什么要动的了。
我建立了一个私有repo用来测试actions,这玩意总是不能指望一次成功。
然而程序运行进度过半时,噩耗传来了。actions上的程序抛出了一个难以理解的错误。由于进程非正常退出,actions直接中断了后续打包上传的过程,弄得我非得再花一两个小时在我自己的电脑上进行全量测试。
本地测试的环节倒是走运,成功复现了与线上环境一致的错误。然而,“走运”揭露出的却是不幸:百度贴吧的rate limit(验证码,反爬,差不多一个意思)恢复运作了。
“恢复”是什么意思?事情是这样的,自除夕以来,一直到昨天,百度贴吧的反爬机制似乎被完全关闭——过去几日的测试流程异常顺利,即便是多次连续进行的全量测试,也没有遇到过任何一次rate limit。而在此之前,百度贴吧有着堪称野蛮的反爬机制:假设不走移动端接口,30个请求之内就会被验证码拦住。
这个问题倒也不算无解,爬虫行业内的一般方法是直接挂个代理池,一个IP臭了就换下一个。对于我来说,直接把我的梯子一块送进actions,开个负载均衡就行。proma的代码已经全部使用https并开启证书验证,即使挂代理也不会有MITM嫌疑。
只是这样一来,工程量又要加了。
以及更惋惜的是,我们错过了最佳的发射窗口。
另一些想说的话
这个项目已经开展整整两个月了,看看在这两个月里,我为此付出了多少:
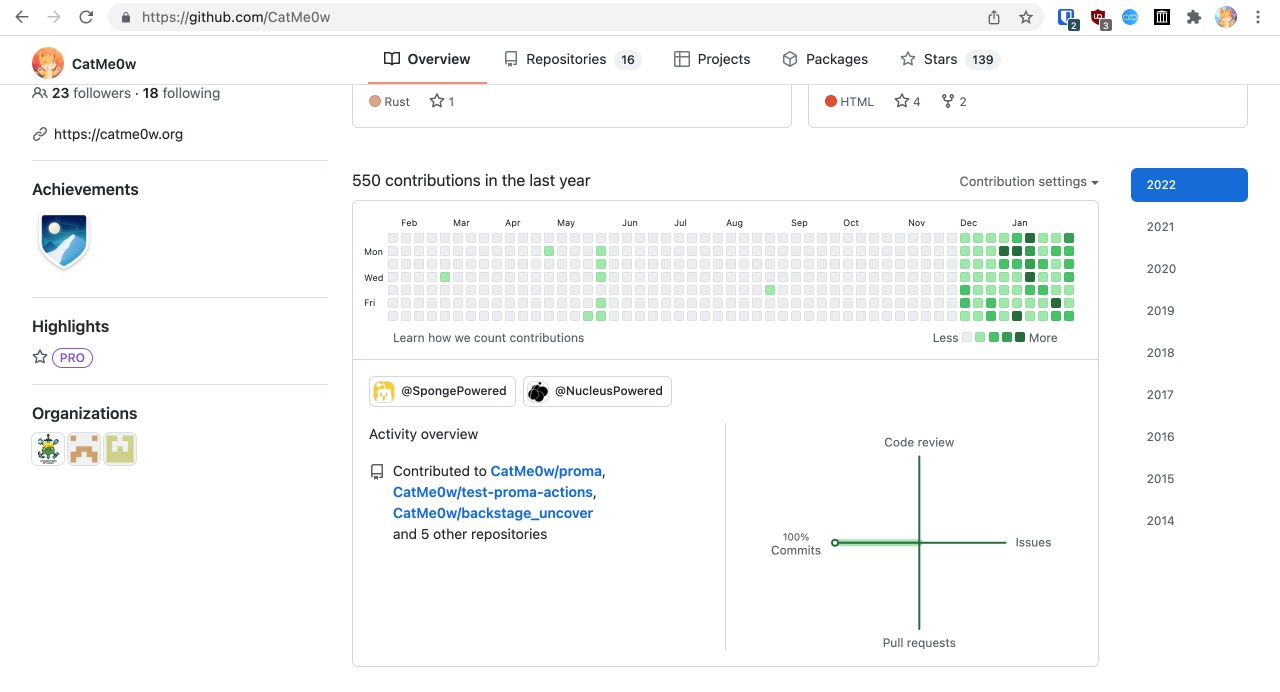
直接造就了自12月以来的全绿瓷砖。
全绿意味着,每天都有新代码提交。
我对这个项目怀抱着巨大的热情,因为,我真的太想看到过去的时光了。
furry,现在也叫福瑞,在大约2018-2019年间出现了暴涨。furry社区的规模在很短的时间内变得空前的庞大,而这量变也引发了质变——furry,仿佛在一夜之间,变得人尽皆知了。现在,在b站随便找个人,他大概率知道什么是“福瑞”;甚至连我的小学同学都有不少已经知道furry了。
furry内部其实早已出现了一些不和谐的迹象,这些迹象正是暴涨所带来的副作用。譬如,在furry被大众广泛知悉之前,内部就已出现了关于“低龄化”“挂人成风”的讨论。
在项目的开发过程中,我看到了过去的人们留下的痕迹,很多很多。那时的圈子是真的小——2013年间,fursuit吧甚至不到一千人。而更重要的,讨论也是真的和谐。在这个次文化刚刚进入国内的最初几年,所有人都怀抱着希望与热情,讨论做装的细节,或者是搬运YouTube上的视频,而绝不会有人撕逼或者挂人。
我们已经回不去了,但至少我们还能在回忆中拥有它。这些记忆的碎片不断激励我继续做下去,势必要把这个项目做完,哪怕最后只有自己愿意看,我也满足了。
……然而这还不是全部。如果只是这么纯粹的目的,我大可不必折腾actions和代理池。然而fursuit吧在2017-2018年间发生的事情,使得我必须折腾,这也正是我的另一半动机。
我给你讲讲我在贴吧后台到底看到了什么:2018年贴吧被夺权后,新上任的吧主是个我们从来没见过的人,而他的真实身份是什么呢?
是爆吧机器人。
他不是furry,甚至不是真人,只是众多买来的机器人账号中的一个。
而在别的地方开团混血狼狗的“飛翔之龍”等人,他们的账号也曾被用于爆吧。
“机器人吧主”上任后的第一件事就是销毁他们自己人爆吧的痕迹,同时也带走了所有狼狗发的帖子,我们的历史没有了。
我真的很生气,但是2018年他们的确把握住了舆论,我们当时也没能夺回贴吧和历史。
能得到今天这个机会,我势必要向世人公开这一切。也正因此,我不能给对方留下一丝一毫舆论的突破口,于是我想到了利用不受人工干预的自动程序“GitHub actions”和开放源代码软件证明我项目的公正性。
code review的小伙伴问我,为啥这么折腾呢,你这也太洁癖了。
我想,我没有别的选择。
(以后我可能会把这里的文章选择性的公开,很显然这一段 大概 肯定 不会在公开的范围中)
2月6日
我收回上一篇所说的“百度贴吧在过年期间放宽了反爬机制”,因为我刚刚发现,似乎我的Windows电脑在任何时间都不会遇到反爬验证码,但我的Mac电脑和actions都会,并且遭遇验证码的速度非常之快。
而我之所以得出上一篇的结论,大概是因为我在过年期间用的都是这台Windows电脑进行开发和测试,因此完全没看到验证码。
邪门,真是邪门。
所有平台用的都是同一份代码跑的,甚至我的Mac和Windows电脑都是同一个IP,到底哪里有差异。
不过所幸我在看到actions上的异常后,选择更换到Mac进行全量测试,否则不可能复现这个问题,就真成了“病原体在实验室环境不繁殖”了。
若是能找到这台Windows电脑不受限制的秘密,就不需要折腾代理池了,运行速度也会更快。
等等,再读一遍昨天那篇文章,我是怎么说的?
“飛翔之龍”被用于爆吧
一切好像都说得通了!我突然理解了这几个相似账号之间的联系。
既然“飛翔之龍”曾用于爆吧,那么无论是有着潜在的炸号风险,还是已经出现了来自百度的账号限制,既然是要用来当吧主的,这个账号背后的用户一定不应该继续使用这个有了“前科”的账号。
如果我的假设成立,那么这就可以解释,为什么“飛翔之龍”的账号已经注销,而后来的fursuit与兽人吧吧主“AbramsDragon”使用了与“飛翔之龍”完全相同的头像。根本是秽土转生。
而“飛翔之龍”我们已经确认,他同时是“大召唤之门”、“软毛蓝龙驭风”、“软毛的须臾”等等。马甲名称众多,只列几个常见的。
还剩一个疑点,那就是现在的“AbramsDragon”,之前的用户名叫做“糊狸狐兔”,而这个账号曾在2018年间用于开团混血狼狗。
现在,你仍然可以通过这个链接看到原始的古战场: https://tieba.baidu.com/p/5686874465
混血狼狗在2018年对古战场做的存档,可以看到当时确实是“糊狸狐兔”的名字: https://www.bilibili.com/video/av23138512
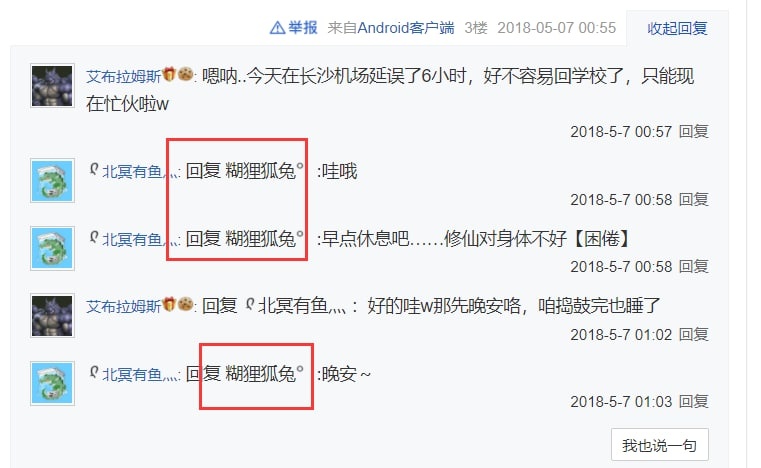
修订:该帖已被删除。也许是我公开这篇研究笔记之后打草惊蛇了,又或许单纯只是他们又在内斗?总之我在这里放一个Internet Archive的存档链接:
https://web.archive.org/web/20220328163719/https://tieba.baidu.com/p/5686874465
回归正题,目前我没有任何明确证据表明“飛翔之龍”和“糊狸狐兔”背后是同一名个体(语言风格差异过大),但至少可以认定两者关系密切。
致所有看到这行字的人:如果项目目前还没有对外公布,千万不可打草惊蛇!至少只有在数据采集完毕之后才能够对外表明此项目的存在。我会先完成数据的采集,再完成静态主页(门户网站主页)。在静态主页完成后才算能够公开。
尽管我最开始的期望是所有东西准备好后再发布,但是后头的时间机器可能工期也很长,如果实在不行,提前公布也并非不可。
2月13日
一个月过去了,我终于收到了来自Starry-OvO的回信。
他没骗我!真的可以让小吧主恢复帖子,而且,甚至还有“单次请求批量恢复”的接口存在,只是因为需求太小,他没做。
要让小吧主有恢复的能力,需要在手机上,由大吧主在吧资料中设置,而这个选项在电脑版后台并不存在。事实上,手机和电脑的贴吧后台俨然是两套完整而独立的系统,电脑版的后台连https都根本不支持,可能自2012年之后就没有积极维护过,也难怪之前在电脑上完全没有找到任何与之相关的迹象。
比这更好的消息,就是我确确实实可以亲自操作了,工作的容错性大大增加。
2月17日
事不宜迟,该开始行动了。
rewinder很可靠,一次就成功了。现在,所有能够查看的,曾被删除的帖子已经全部释放出来,我也紧接着开展了proma与uncover在本地与线上环境的测试。
proma要改的东西不少,释放出来的帖子里不少年代久远,有着各种各样奇怪的数据结构,得花一些时间专门适配。
好消息是,第一页帖子完全不受影响,短时间内不太可能被人发现,这意味着我的时间比预想中充足很多……当然,除了最近几天被删除的帖子,但愿他们不会注意到这个误差。
另外有件事让我挺乐的。他们当年买了不少成品的爆吧服务,贴吧里被塞进的四万1级号就是他们的杰作。只是这些纯机器人已经被百度屏蔽得差不多了,这些“外援”产生的爆吧痕迹并不是很明显。
但是刺激的来了,这伙人还用自己的大号去接入爆吧程序,由此产生了一个奇观:他们在fursuit吧爆吧的同时,在兽人吧倒打一耙,开团混血狼狗。而且,现在他们仍然能被观测到的爆吧痕迹比纯机器人还要多。
真的乐坏了,他们怎么敢,怎么敢直接拿同一个号爆吧和挂人……
在有了空前充足的数据后,我花了一些时间寻觅那些撕逼的古战场,尝试彻底搞清当年爆吧那伙人,也就是通常称作的LL,他们的人员结构。
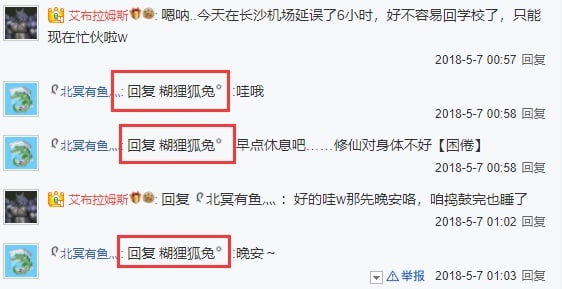
在结合Internet Archive、本地数据库、狼狗的录像,以及当前的贴吧状态下,我终于彻底锤死了:艾布就是软毛。
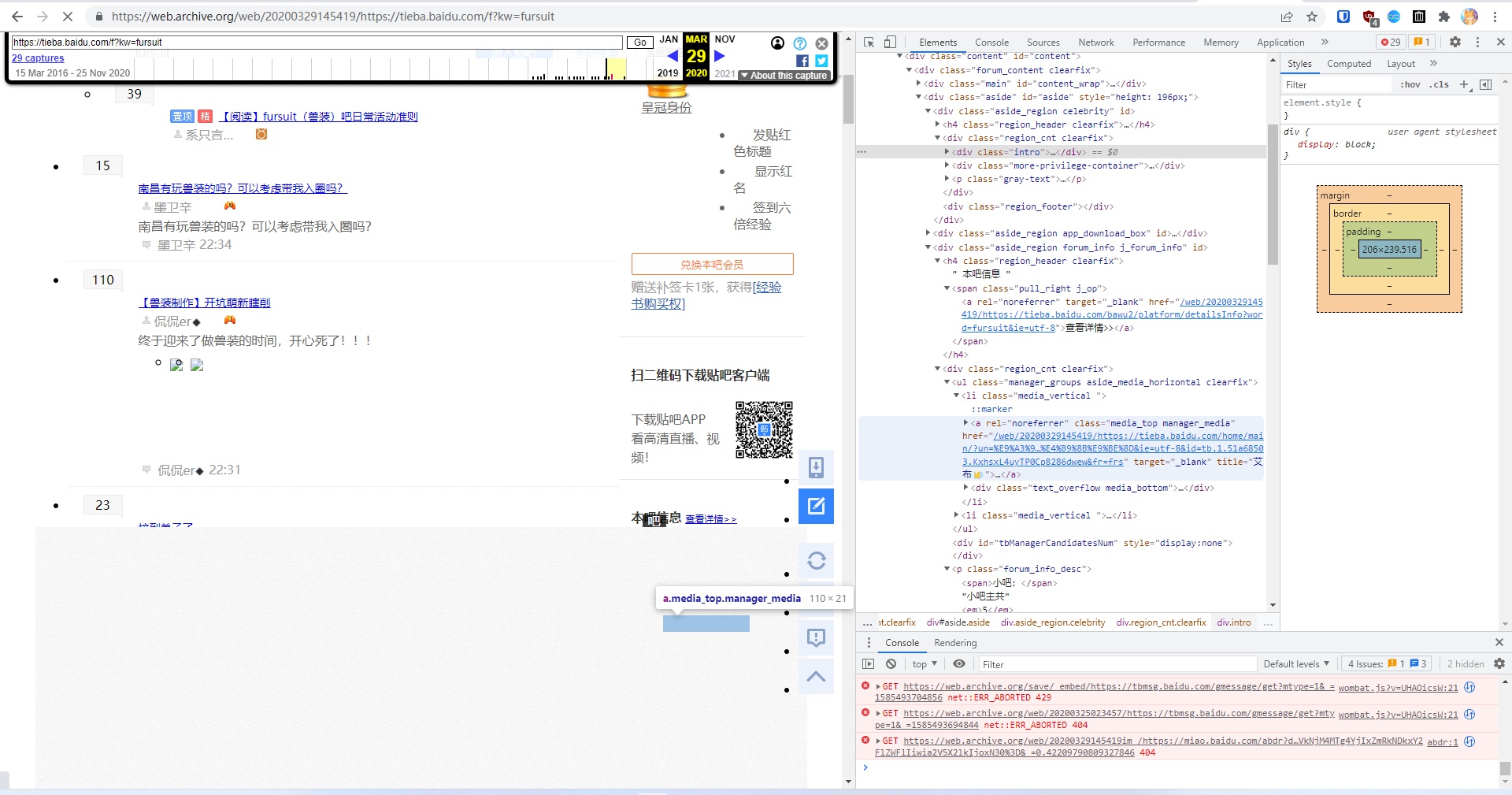
Internet Archive在2020年3月的存档,排版有错乱,吧主的头像被遮挡了,但通过链接可以看到有“艾布”的名字

吧主的用户链接,出现了“艾布”的名字,注意这个
tb.1...的部分,这是百度账号的唯一标识之一
移除遮挡之后看到的头像,软毛(“飛翔之龍”)曾使用过相同的头像
“飛翔之龍”爆吧的帖子,账号注销后名字在公开贴吧已不可见
从数据库中找到的记录,爆吧者的用户名即为“飛翔之龍”,而
tb.1...的字段与2020年3月的吧主“艾布”相同,即相同账号
(感谢Internet Archive送上助攻)
但是我仍然没搞清楚“艾布拉姆斯”和“糊狸狐兔”之间的真实联系。
这里是内部文档,不公开的,我就直接说了:如果要造势,那就直接锤他们是同一个人,毕竟,下面这个是没办法洗的(尽管也可能就是同一个人):
显然我不可能亲自下场开团,但我们终于重新掌握了话语权,我们已经有了反攻的能力。
修订:此处分析全错。详见:https://www.zhihu.com/question/327443124/answer/709795424
2月27日
中期完成了。
现在,所有暂时释放出的帖子已经被删回去了,贴吧恢复到与去年12月之前完全一致的状态了。
后期主要由两个部分构成:前端和后端,也就是我们自己设计的“贴吧模拟器”。
前端就是网页,给最终用户看的;后端就是和数据库对接的服务器部分,处理数据库查询结果,呈现给前端,再由前端显示出画面。
没有了前期开发那么多的不稳定因素后,终于可以在后期整点活了,比如,尝试一下最新最潮的技术……
3月26日
我太懒了,懒得更研究笔记了。
总之,后端开发已经完成而且上线了。这意味着,后期已经完成了一半,只要完成前端,就可以正式发布了。
后端的开发过程其实还挺艰难的,这玩意要实现的逻辑比我一开始的预想复杂许多,中途也遇到了不少困难,不过最终还是挺过来了,整出了还算能用的成品。
现在,前端开发才刚刚开始。折腾Node.js和那一大堆傻不拉叽的打包工具和包管理器就浪费了我一整天的时间。前端开发真的是一个非常,非常,非常不健康的社区,每隔几个月,GitHub上就会出现一批你闻所未闻的新项目,而且个个自带两千以上的star;每一个新项目都有着“收拾以前的所有屎山”的宏伟梦想,但它们的归宿永远都是成为屎山的一员,之后再被新的屎山尝试收拾,如此往复。
不过最终对于要使用的工具和框架,我还是心中有数了,然后,就来到了前端开发的第二个难题:平面设计和文案。。。
设计和文案是如此难做,以至于即使我在前期就开了坑,到现在馕字还没一撇,虽然中途推翻过几次。