fursuit吧:檔案館與時間機器
本文原載於「fursuit吧:檔案館與時間機器」專案主頁。
嗨,我是貓喵,「fursuit吧:檔案館與時間機器」的作者。首先,感謝你看到這裡!
“檔案館和時間機器”是我投入最大的專案之一,這既是一次為furry(儘管主要是fursuit)“尋根”的嘗試,也是我送給自己的禮物——一直以來,我都非常渴望能夠修復這些,本來以為早已永久丟失的資料。如今,我終於得到了它,而創造這份禮物的不是別人,正是我自己。要我說,當我看到它執行起來的那一刻,我可比誰都開心——
話又說回來,既然你已經來到了這裡,那麼你一定想了解這個專案的前世今生,或者,你有想問我的問題,準備好,讓我們暫時回到2012年的夏天……
原點
2012年6月,在一個早已被我淡忘的契機中,我誤打誤撞來到了百度貼吧fursuit吧。
映入眼簾的,多是從各處搬運來的獸裝圖集,一般是某位fursuiter的返圖合集;此外還有不少搬運自YouTube的影片,比如EZ Wolf的《江南style》,或者Keenora的獸裝高空彈跳。
我難以描述我第一次看到獸裝的感覺,這是一種……我從未見識過的東西。很神奇,很微妙。
很迷人。
我想著,那麼留下來吧。
我對這個前所未見的新事物很感興趣,但同時又小心地保持著距離感。我沒有立刻按下加入貼吧的按鈕,只是隔幾天回來看一下最新的帖子。
吧裡流行的東西時刻發生變化。以我那麼不頻繁的上線機會,幾乎每一次來,首頁的畫風都有不小的變化。
有一次,首頁靠前的幾個帖子都是“3D圖”,其實就是在左右兩邊擺上相同的圖片,然後用鬥雞眼看出3D效果。
但這時還在2012年,國內的第一套獸裝全裝要到2013年才出現。
我那時不知道furry,也沒往動物的方面想。甚至,我在fursuit的世界混跡了好一陣子才意識到furry這個“上游”的存在。
時間來到2015年,國內舉辦了歷史上的第一次獸展,“神州萌獸祭”。
在這個時間,我們已經有了好幾套像樣的獸裝,基本都是自制。我們離脫離田園時期還遠著呢。
但很可惜,那個夏天我正在為自己的Minecraft伺服器合夥人跑路的事情焦頭爛額,完全錯過了這場值得銘記的大事件,以至於我對2015年的首次獸展沒有太多印象。
事後想來,這實在是撿了芝麻,丟了西瓜。Minecraft從未給我除了遊戲內容以外的快樂,開伺服器實屬自找不痛快,為什麼不把精力放在能讓人放鬆的事情上呢?
又一年過去了,此時是2016年。
那個盛夏,永遠都會是我心中最經典的獸展,它叫“獸夏祭”。
至少在fursuit的世界,那個夏天是一場空前的狂歡——我們已經有了不少相當強悍的裝師,有了全場手腳並用都數不過來的獸裝。而獸展的歡樂氣氛甚至傳播到了人類世界,為這個在當時小眾得不能再小眾的圈子注入了大量新鮮血液——我們的人數,能以千為單位了。
而“獸裝直播”的熱潮,也正是從那時開始發跡。
卡農現在的名字叫流銀,小獸現在的名字叫艾爾,而火喵還是那個火喵。
度過了一個難忘的夏天之後,我們走向了2017年。
可惜,2017年的獸夏祭不盡如人意,可以稱得上是譭譽參半。
但在此之外,更嚴重的危機正在醞釀著……
我們所知的歷史即將迎來終結。
末日
正如你們已在檔案館主頁看到的那樣:
2017 年 6 月 19 日,吧主“混血狼狗”職位被百度撤銷。
2017 年 6 月 20 日,使用者“布偶新世界”宣稱對原吧主意外下臺的事故負責。
2017 年 6 月 23 日,fursuit 吧開始遭受爆吧。
……
2017 年 6 月至 2018 年 7 月,fursuit 吧間斷遭受爆吧,時間跨度一年有餘。
期間,吧主權力多次更迭,建吧早期的精品貼幾乎被全部刪除。
象徵國內 fursuit 文化的亞歷山大圖書館,在頃刻間被焚燬。我們的歷史沒有了。
2018年,在一整年的戰火紛飛後,一切似乎已塵埃落定。原有的吧務團隊被徹底清洗,取而代之的是“艾布”和“糊兔”,以及許許多多他們自己的手下。
他們不光清洗了吧主團隊,還把他們的發帖,連同大量其他人的精品貼,盡數毀滅。
fursuit在國內的發展歷程,一瞬間斷了根。
故事的結局是,他們完全接管貼吧後,所有的爆吧機器人和偶裝廠,在一夜之間全部消失了。
我後來才知道,在他們得手後的這三年裡,後臺的操作記錄總共不到50條。其中30餘條還只是清理之前的爆吧痕跡。
貼吧停擺了,這種發展完全停滯的狀態持續了三年,就像小說中描述的那樣,是”光明的中世紀“。
我不知道他們為什麼要這麼做。我很想質問他們,這麼做對你們究竟有什麼好處?你們想要偷取貼吧,那給你們便是,為什麼要破壞文明,破壞歷史?
你們費盡千辛萬苦得到它,只是為了毀掉它嗎?
“艾布”、“糊兔”、“軟毛”、“LL”、”大召喚之門“,所有這些人的名字和身份全部交織在一起,擰成一團亂麻,我甚至不知道我到底應該找誰。
我不知道他們是誰,但他們是我最痛恨的一群人。
上部:曙光
2021年11月的一個午後,我做了個夢。
那是一個很大很大的劇院,關了燈,只有我站在聚光燈下。
這是一次獸展,但此刻看起來完全是蘋果公司開發佈會的樣子。而我此時正站在蒂姆·庫克該出現的位置上。
我面向面前黑壓壓的人群,舉起了一張光碟。這就是我要釋出的東西。
這張光盤裡裝有已經復原的,fursuit吧的完整副本,包括所有被艾布們毀滅的資料。
我把資料恢復了,就在這張光盤裡,而現在我要把它給全世界看。
見鬼去吧,艾布。你們沒能得手。
……
我醒了。
我醒了……
……
要是夢裡的東西是真的,那該有多好。
多好啊……
要不,去看看吧。看看現在那裡怎麼樣了。
那裡沒有吧主了。他們離開了。
而此時正有一個人正在嘗試重新申請吧主,她叫“冰清”,一個我從來沒見過的名字。
我自己的百度帳號在艾布們降臨的那年就登出了,我沒辦法親自上陣,如果冰清能成功拿下吧主,找她幫忙就成了唯一可行的路。
幾天之後,冰清如期成為了新吧主。
那麼,輪到我登上歷史舞臺咯。
我要改寫歷史。
下部:Creatio ex nihilo(無中生有)
有希望了,有希望了。
我開始頭腦風暴,思考我能做什麼。
是直接恢復,還是搞得更大一些, 比如做個賽博遺址公園什麼的?
不過在此之前,我得先弄清楚當年到底發生了什麼。我得去找她,讓她把我撈成小吧主,我只有親自看到後臺歷史記錄才能明確接下來的動作。
冰清很快就答應了我。非常感謝她,能給予我一個陌生人這麼大的信任。
但當我真正看到後臺的那一刻,我還是愣住了。
在此之前,我已經猜測過好幾種可能的情況,但實際發生的仍然完全超出了我的想象。
“play月光如水k”,他是誰?破壞都是這個帳號做的,這個帳號刪除了幾乎所有精品貼。
而我根本不知道有這號人存在過,我從來沒在貼吧裡見過這個人,無論是帖子裡還是吧務名單。
更糟的是,這個號已經登出帳號,我也查不出他的任何過去。
和“play月光如水k”一起登出跑路的還有“飛翔之龍”和“大召喚之門”等好幾個人,比這更蹊蹺的,是當年“糊兔”的帳號現在變成了“艾布”的名字,對此我想不出任何合理的解釋。
算了,別浪費時間在覆盤這些抽象人的行徑上了,現在只有一件事情重要,那就是資料的完整性。
我聯絡上了我的好幾個高技術力的夥伴,在經過又一番頭腦風暴(儘管多數時候完全是我自己在對著空氣講話)以及好幾次推翻計劃後,我最終明確了我要做的東西:
一個可以回溯貼吧歷史上任意一刻的“時間機器”。
它的代號叫Project Ex Nihilo。
“無中生有計劃”。
我根本不知道我有多大把握,但我得試試,我要把資料恢復得儘可能完整。
以及……我要把我現在做的事情都記錄下來。我不能再讓更多的東西被遺忘了。
六個月後
https://fursuit.catme0w.org 正式上線了。
這是孤獨的行為藝術嗎?我不知道,也許我可以因此一炮而紅,也許不會,只是獨屬於我一個人的感動。
但至少,我看到了我想看的東西。
關於我開發這個專案的心路歷程,真的有太多可以說的了。
從開發的第一天起,我就時常會把我自己的感想寫下來。這些原本是用作參考和內部分享,但現在我打算把它們原封不動地給你們看。
與其在這裡重新回憶和轉述一遍當時的靈感,或許直接讓你看到我當時每一天的想法、見聞和進展,要更真實,更震撼些。
如果你已經看到這裡,非常感謝你的陪伴,接下來請一定一定要點進去看,這全是我心血的結晶。
那麼,祝閱讀愉快。
(包含較多的技術內容,對於沒有相關知識的讀者可能略顯難懂。)
尾聲
如果你去查詢我的域名 catme0w.org 的證書籤發歷史,你會留意到在2017年中旬,時間機器的域名 https://fursuit.catme0w.org/ 就已經出現過了。
當時貼吧剛被偷家,另起爐灶是當時主流的聲音之一。
不少人想以此為機會建立論壇,進行數字大遷徙。
我也不例外。
可惜,我很確定直到今天也沒人再建立起成規模的論壇。
不過我最終還是在這同一個域名上,看到了我想看的東西。
如果你已經讀完了我的研究筆記,你可能會疑惑為什麼筆記在3月就戛然而止了。
這一點倒是沒有什麼太多神秘的原因,單純是因為我太懶,以及編寫“貼吧模擬器”不少時候像是體力活,例如微調介面樣式等等。
然而六月正式釋出的版本其實遠遠未達到原定設計中的預期,它仍然是一個半成品。
我後來去忙一些自己的事情了,反正這個版本暫且能用,就先放著了。
轉眼到了九月,對creatio(時間機器前端程式的專案名字)來說,新的危機出現了。
The story behind the scene of this website is truly epic, but it is still far from finished. After about June last year, I noticed there was a critical SEO failure and it eventually wiped all of itself from Google search results, and the only way to fix is a big overhaul.
One of my friend joined the development, but we immediately ran into a trouble. Something really, really bad happened, caused the overhauled version indefinitely postponed.
I am never a good programmer. You can see through the source code of the original version, but also the only version available: https://github.com/CatMe0w/creatio
I’m also not a talented one. Under the hood of this “megastructure” is shittily shitty shitcodes. And that leads to the final collapse - not the collapse of the project, but -
me.
https://twitter.com/XCatMe0w/status/1651291197112193027
https://twitter.com/XCatMe0w/status/1651291197112193027
不過,這是另一個故事了。
尾聲之後:希望
https://www.youtube.com/watch?v=BxV14h0kFs0
《這個影片有58,394,109次觀看》(This Video Has 58,394,109 Views)
作者 Tom Scott
“計算機歷史博物館裡中的軟體和硬體,有些在我成長的過程中貫穿始終,我很懷念這些東西,因為它們能自己保持執行,它們不需要來自公司的持續維護。
但是如果你所做的東西依賴於其他公司的服務,那麼……存檔就會變得非常非常困難。
每隔幾分鐘,我的程式碼就會在YouTube查詢這個影片有多少播放量,然後更新影片標題。
也許在你看這個影片的時候它還在工作。
但最終,它會停擺的。
YouTube也會如此。
一切都會如此。
熵,逐漸下降到無序狀態,這是宇宙的基本規律之一…
……熵,最終會把我們全部毀滅。
這就是我選擇在這裡拍攝的原因。
多佛白崖是英國的象徵,是這道雄偉的屏障,但它們,本質上只是石頭而已。
時間和潮水會把它們沖走,在很久很久以後。
這個影片,也會消亡。
但這並不意味著你不該創造。
儘管最終會消亡,並不代表不能產生影響——延續到未來的影響。
快樂。奇蹟。笑聲。希望。
世界可以因為你在過去創造的東西而變得更好。
雖然我確實認為,人類的長期目標,應該是找到擊敗熵的方法,但我很確定現在還沒有人知道該從哪裡開始解決這個問題。
所以,在此之前,請儘量保證你所做的事情能推動我們朝著正確的方向發展。
它們也許不是很龐大的專案,甚至,也許只有一個觀眾。
即使不能永恆存在,也要努力讓它們留下一些積極的痕跡。
是的,在將來某天,更新這個影片標題的程式碼會失效。
也許我會修好它。
也許不會。
但那段程式碼,從來都不重要。”
鳴謝
感謝為我提供幫助的專案(儘管我完全沒有使用它們的程式碼),以及伴隨我一路走來的朋友們。
排名不分先後。
可能有遺漏。
專案
https://github.com/Starry-OvO/aiotieba
https://github.com/52fisher/TiebaPublicBackstage
https://github.com/cnwangjihe/TiebaBackup
https://github.com/Aqua-Dream/Tieba_Spider
朋友們
Aster
mochaaP
LEORchn
ShellWen
NavigatorKepler
為此專案編寫的 GitHub 倉庫
https://github.com/CatMe0w/fursuit.catme0w.org
https://github.com/CatMe0w/ex_nihilo_vault
https://github.com/CatMe0w/backstage_uncover
https://github.com/CatMe0w/proma
https://github.com/CatMe0w/rewinder_rollwinder
https://github.com/CatMe0w/proma_takeout
附錄:Project Ex Nihilo路線圖
前期,資料提取準備:
取得貼吧後臺日誌,確認修復的可行性和資料完整性
- 資料修復可行,但似乎沒有辦法在不恢復帖子的情況下,直接通過後臺匯出完整的帖子內容。
編寫後臺日誌匯出工具“uncover“
匯出全部後臺日誌到sqlite資料庫中,同時保留一份原始html
這部分在本地進行,資料無需公開。
(下載 uncover.db.xz)
根據前一步匯出的資料庫,統計總共需要恢復和再次刪除的帖子
- 後期的爆吧機器幾乎無法與真人帖子區分開,簡單地說樸素貝葉斯肯定行不通,若人工分析的話工作量過大(甚至人工也無法區分),同時為了保證專案的中立性,計劃直接恢復後臺日誌中所有被刪除的帖子,不區分真人或爆吧。
恢復的順序:時間順序,由近向遠
刪除的順序:由遠向近
重新編寫爬取所有貼吧公開帖子的工具”proma“
原定計劃為基於Aqua-Dream/Tieba_Spider魔改,但由於過於容易撞到反爬,
並且無法保留完整原始資料,以及這一專案沒有開源協議,還有魔改工作量過大,因此計劃變為完全重寫。計劃使用selenium,單執行緒,或grid+多job執行,儲存為warc存檔格式。草案:將處理html並輸入sqlite的部分解耦,之後編寫後續工具,直接使用warc檔案作為資料來源,不使用百度的線上服務。- 除Aqua-Dream/Tieba_Spider的全部功能外,還需要另外實現的部分:
- 草案:使用cnwangjihe/TiebaBackup中的手機端api取代電腦版網頁+html parser
- sqlite替代mysql
- 接入代理池
- 爬取簽名檔
- 爬取暱稱
- 爬取頭像
- 可選:爬取紅字或加粗格式
取得一個大吧主的BDUSS,供批次恢復和刪除帖子- 小吧主沒有恢復帖子的能力,
這是唯一的辦法了。 - 格局開啟中,詳見1月10日研究筆記
- 小吧主沒有恢復帖子的能力,
在大吧主BDUSS的幫助下,編寫自動化恢復和刪除帖子的工具”rewinder-rollwinder“
這個工具的編寫需要大吧主的BDUSS,用於找到與恢復相關的介面。- rewinder:恢復被刪除的帖子
- rollwinder:rollback the rewinder
中期,資料採集之夜:
(行動名稱:決勝時刻,The Showdown)
- 開動rewinder,恢復歷史中所有被刪除的帖子
- 這部分可以在本地執行。
- 爬取並公開所有帖子
- 這部分將使用GitHub Actions執行,爬取的資料將直接上傳releases(附帶sha256sum),確保整個流程不存在人為干涉。
- 把所有帖子送入Wayback Machine
- 確認資料有效後,開動rollwinder,批次刪除這些帖子(回滾rewinder的全部操作)
- 這部分可以在本地執行。
- 匯出並公開後臺日誌
- 這部分也將使用actions執行,資料也是直接上傳到releases,這部分資料將作為日後其他環節的基準資料集。
後期,資料處理與展示:
- 給專案想個好聽的名字
- 撰寫靜態主頁的文案
- 編寫靜態主頁的前端介面
草案:鑑於我根本不懂設計,比起自己糊一個觀感並不算好的主頁,考慮使用HTML5UP或Carrd等模板進行魔改。- 還是要自己畫介面
- 編寫時間機器的前端介面
- 編寫時間機器的後端介面
- 用於讀取uncover和proma的資料集,以json格式呈現給時間機器前端。
若使用cloudflare workers,編寫關係型資料庫轉換為workers kv的工具。- kv是大便,得找個東西存sqlite資料庫
後期前後端開發todo list
前端
- 主頁內容
- 下載頁內容
- 搜尋框
- 可互動的評論元件
- 影片播放器
- 檢視器footer
- 吧務後臺設定項
- 語音播放器
後端
- 腦回路正常的搜尋實現
- 重寫並上雲
尾聲,正式上線與後續專案:
- 想個好一點,能吸睛的宣傳文案,在空間等地方釋出
- 若專案成功,考慮開啟後續專案:群星計劃
- 一個供使用者提交和存檔已絕跡福瑞內容的平臺,人工稽核,以torrent等方式分發,不破解付費牆。
純開腦洞部分:
- 將所有的資料集和原始
warc檔案刻錄在M DISC等適合長期儲存的介質,搞個什麼collector’s edition(? - 給專案畫個福瑞吉祥物(??
附錄:研究筆記
2021年11月29日
突發奇想,回到fursuit吧看看,我原本以為那裡還是一片廢墟。一回去可不要緊,我說對了一半,確實還是一片廢墟,但是吧主沒有了。他們離開了,或者說是被百度弄下去了。
等了三年,終於有希望了?
11月30日
百度貼吧的後臺是可以恢復被大小吧主刪除的帖子的。混血狼狗在fursuit吧幾乎所有的發言被剿滅,我不太相信這是百度做的。若是百度所為,應該直接讓他的號完全不能被檢視才對。
當下,有一個人,不屬於他們的一位,正在申請吧主。我手頭沒有像樣的百度賬號了,僅剩的兩個一條發言都沒有,這樣的號申吧主肯定沒指望,不然我肯定要插一手。
那麼,如果那個人能搞到吧主,或許能找到他,幫我們重新匯出歷史資料。這樣或許能建立一個賽博圓明園遺址公園什麼的,象徵2011-2016這段國內fursuit文化的田園時代。
12月4日
他上了。目前他也是fursuit吧和獸裝吧唯一的大吧主。
修訂:應為“她”。下同。
我聯絡到他了,我正在問他能不能把我撈成小吧,然後我可以親自接入後臺,考證那些資料是否有修復的可能。
我考慮過更溫和,更不引人注目的處理方式,但我實在想象不出當年到底發生了什麼,可能實際發生的事情遠超我的想象力。無論如何,在一切都是未知的情況下,思考皆是空想,一切只有在接入後臺之後才能做下一步判斷。
我希望儘可能不改變當前貼吧的狀態,只把資料複製一份,自己建立一個不受百度控制的賽博遺址公園。
成為小吧的話,我應該可以提取所有資料,再不濟也能提取一個標題。只是資料清洗一定很麻煩,畢竟爆吧的記錄應該不少。
接下來我準備買個域名,開個網站來存放資料,打包的資料就用torrent分發,現在我要寫一下文案了。
這就是艾斯吧的操作,我們就要做到了!
(“艾斯吧的復仇巨瓜,吃笑了所有人” https://zhuanlan.zhihu.com/p/159644849)
12月6日
我上了。
我的所有猜想都被證實了。後臺呈現出的景象一言難盡,幾乎可以用光怪陸離來形容。狼狗在田園時代搬運的帖子的確被全滅,操作人是一個叫“play月光如水k”的賬號。我從未見過這個賬號。他是誰?
包括“play月光如水k”在內,“飛翔之龍”和“大召喚之門”等幾個賬號都已不復存在。他們登出賬號了。還有更蹊蹺的事情:2018年間,“糊狸狐兔”的百度賬號現在變成了“AbramsDragon”的名字,這一點我找不出任何合理的解釋。
我還是不要再浪費時間嘗試覆盤2018年間的大亂鬥了,即使弄清楚了又如何呢,不過是再掀起一次撕逼的狂潮罷了,沒法解決任何問題。
只有一件事情值得關注,那就是資料,資料的完整性。
12月7日
我花了三個小時部署好這個軟體,php和url重寫真的是煩死人了,一想到過去的程式設計師和運維需要和這些東西打交道,就慶幸自己真是生在了一個好時代。
https://catme0w.org/ekr3ceijfeac6e2iyjt4d7f4/
這個東西可以把貼吧的後臺投射到公共網際網路,這樣我就可以讓一些其他人頁看到當年真實發生的事了。當然,我還不確定要發給誰。
說實話,我不太希望過去的貼吧領導班組介入這件事,否則可能會影響(輿論上的)中立性。整個工程在輿論上的地位是非常重要的,畢竟明眼人都能從後臺日誌看出發生了什麼,我必須在輿論上立於不敗之地才行,不能有任何風險。雖然,要說這世上對此最應該有知情權的人是誰,也只能是這幾位親歷過這事的老人們了。
這個程式只是個臨時介面,之後要如何收集、修復和整理資料,恐怕是個難題。
首當其衝的是,我們從貼吧後臺看到的已刪除的帖子,如果是主題帖,只能看到一樓的頭幾個字,其餘的部分完全不可見。要訪問這些記錄,必須恢復整個帖子,那麼這就不可避免地會修改現在的貼吧。
如果放遠一點,假設我們用這種方式去檢視所有被刪除的帖子,就意味著我們需要把它們全部恢復。這對於貼吧絕對算是另一種程度的毀滅性打擊了。
當然還有一種方式,就是恢復所有帖子,爬下來之後,再把原本被刪除的帖子重新刪一遍。
這種方法的缺陷也顯而易見:首先是所有被刪過帖的人,他們的“系統訊息”會被我們輪一遍;更嚴重的是,如此操作會讓貼吧後臺日誌變得面目全非。最大的問題是,在這麼一通現實重構般的操作後,我們如何保證整個貼吧真正恢復到“我們來之前的原樣”——簡單地說,如此一來,我們在輿論上會佔下風。
於是,現在最主要的問題就是,急需找到一種不恢復帖子就能獲取被刪除帖子完整內容的方法。
然後是不那麼嚴重的問題:我們要建立什麼樣的檔案館。
現在,假設我們已經能夠匯出貼吧的被刪除帖子的完整內容,不管是使用什麼方式。我原來的想法是,只建立一個2016年左右的“快照”——即在那個時間點的貼吧狀態。但是我親自接入後臺後,發現這其實很難:如果要精確還原到2016年的狀態,就必須分析貼吧後臺的所有日誌;單獨回退某個人的全部操作,得出的結果是不準確的。
那麼我們不妨直接實現一個更遠大的目標:將當前貼吧狀態和所有的後臺記錄結合在一起,製造一個可以回溯任意一刻歷史狀態的“時間機器”。
於是,這樣會引出一個新的問題:在我們創造時間機器之後,將來新出現的帖子和操作怎麼辦?我們已經暴露了貼吧過去的一切,包括每個吧主的每一次操作。
簡單地說,我們會讓貼吧失去將來的存在價值。
為了解決上述問題,我考慮了一個不那麼激進的方案:
假設我們最終沒能找到不恢復帖子來提取完整內容的方式,那麼我們只能透過完全回退某幾個刪帖機的行為,來恢復一些最有價值的帖子,這其中大多是混血狼狗的。
然而,接下來,我們所做的一切將陷入一個極度尷尬的狀態:既然貼吧已經恢復了,為什麼還要捨近求遠,去觀看民間的備份呢?
對於我們來說當然不是這樣,我們深知百度的無底線,備份是必須要做的;但是大多數人認識不到這一點,或者儘管能意識到,但是光是訪問速度和易用性上的差異就能讓大多數人放棄了。
現在很可能無法找到完美的方案了,做出取捨恐怕無法避免。
比起這個,還有一個更要緊的問題:必須儘快再扶持兩位大吧主上任。
目前對方近期仍在獸人吧活動,放棄fursuit吧很有可能只是一個意外。按過往經驗推斷,只有一個大吧主的獸向貼吧非常容易被舉報掉。我本來是不想自己上大吧的,但是考慮到可能要進行大規模的帖子恢復操作,可能還得我自己上。
那麼,還得再找一個人,甚至還得準備好幾個替補。
下一步:將當前狀態的貼吧後臺和所有公開可見貼吧內容進行完整提取。儘管具體方向仍不完全明確,有些事情是可以先做起來了。
正好是因為程式碼古老,百度貼吧的前端幾乎沒有使用js,這意味著我不需要使用selenium。只要requests下載html,然後餵給html parser,就可以產生出我們需要的資料結構了。
12月8日
https://github.com/CatMe0w/backstage_uncover
匯出後臺日誌的程式原型已經做起來了。昨天和一位技術顧問聊了一下,計劃採用sqlite儲存。
其實我一開始根本沒往資料庫的方面想,經他一點我才意識到問題。我本來打算隨便搞個json存一下就算了,但是資料量可能會非常龐大——數十萬行對於sqlite來說只是基本操作,但數十萬行的json就吃癟了,這還不算query的耗時差距。
我正考慮在程式完善後,讓github actions來執行並匯出資料。主要還是輿論方面的考量。因為說實在的,後臺記錄中的東西實在是太……難以置信了。醜話我就不多說了,意思到了就行。
讓actions執行,就是讓actions執行那一刻倉庫裡的程式,爬完資料後直接上傳到releases,再附上sha256sum,確保從程式碼到執行環境,再到最終的釋出流程中,沒有任何一個環節可以人為干涉和篡改資料。
貼吧後臺的HTML也屬實一言難盡。HTML結構倒是還算規整,但有一些資料總是缺斤少兩,或是本身就呈現得亂七八糟。例如有一些<li>的文字前後帶五六十個空格,或者是發帖日期沒有提供年份等等。
年份的問題,一開始我們打算爬一下對應帖子前後的帖子,透過臨近的帖子來算出年份,但是很明顯這樣魯棒性(robustness)不佳,爬多了還有可能撞反爬。
Aqua-Dream/Tieba_Spider的貼吧爬蟲似乎相當符合我們之後爬公開貼吧的需求。主要的缺點就是它使用mysql而非sqlite。我們不需要mysql。
我試著跑了一下這個程式,情況比我們想象中的嚴峻:目前的貼吧共有34頁,如果把被刪除的帖子全部放出來,這個數量還得再擴充一倍;而這個程式在爬到最多不超過29頁時,就會被反爬驗證碼攔下來。
對於我的本地環境來說,這倒是很好解決,接入我的梯子,梯子給個負載均衡就行。但是對於actions,情況就棘手很多了。看了一下相關issues,最合理的解決方法應該是魔改程式碼,接入一個公開代理池。
結合了技術顧問的一些建議,基本上確認接下來的操作路線了。
目前操作日誌的總數是5126,其中“刪帖”佔了4291條。
找一個夜深人靜的時候,將所有刪除的帖子全部恢復。完成之後,完整爬取整個貼吧,最後將恢復的帖子刪回去。從外面看上去就是無事發生,除了有些使用者的“帖子被刪除提醒”可能會被轟炸一下。
這個方法的確有一些離譜,但是在百度極為糟糕的管理制度和程式水平之下,這應該是最好的方法了。
最後的最後,將後臺的操作日誌再爬一份出來,合併兩個資料集,基本上就是貼吧有史以來的完整記錄了(除了被百度刪除的,那些吧主也看不到,任何人都看不到)。
把所有資料拿到手之後,這一階段就算完成了,之後的工作就完全與百度的服務無關了。
12月9日
另一位顧問提議我儲存warc檔案。
warc是一種類似mhtml的格式,可以最大限度地儲存一個網頁載入的過程和資料。同時,有了warc,甚至將來還能上傳到wayback machine(在確保整個爬取流程可信的情況下,即前文中提到的actions執行)。
但問題是,Tieba_Spider不使用瀏覽器,根本不可能儲存可供重放的warc。Tieba_Spider做的事情只是單純下載html,抽出特定文字,然後輸入資料庫。
如果需要warc,我需要重寫整個工具。
我想到了一個精妙,但其實做起來非常弱智的方法來判斷髮帖年份:找到全貼吧每年第一個帖子,把他們的id硬編碼到我的程式碼裡,這樣就可以在不發起任何額外網路請求的條件下精確判斷年份了。
若是使用人力二分法,尋找這些帖子應該很快,但實際上這個過程花費了我超過一個小時的時間。因為我在手工遍歷的過程中,發現全貼吧至少有90%的帖子都消失了。
具體來說。是90%的id是空的。其中大多數是被刪除,少部分“賬號被隱藏”,少部分是空白錯誤,還有一個“貼吧被合併”。
所以我們損失了90%的過去。
12月10日
我在修uncover剩下的bug時逐漸被氣出腦溢血。
我發現了一批在2019年發帖的ip匿名使用者。2019年哪來的匿名使用者?我到底要為貼吧這個垃圾產品補充多少的edge case處理?
Tieba_Spider還有別的問題。它不能爬取暱稱,而如果只使用使用者名稱,無疑是很不妥當的,很多人改暱稱就是為了不再頂著一個黑歷史般的使用者名稱。
貼吧的網頁版不是前後端分離架構,若使用電腦版進行爬取,需要處理html。有一個使用手機端api的爬蟲,但功能與我們的需求不完全重合:cnwangjihe/TiebaBackup
使用手機端api,或許能夠規避反爬……?
答曰,不能。手機端api同樣會撞上那個傻子旋轉驗證碼。技術顧問想要正面迎戰這個驗證碼,找一個自動化識別它的方式,但我其實主張繞過它,用代理池或者selenium。
這個專案的所有程式碼必須保持最簡單最直接的設計,尤其是堅決不能炫技,炫技必然引入複雜性,一複雜,不穩定的機率就大了。
傳來噩耗:現在的百度貼吧,只能申請一個大吧主了。這個公司為了流量真是無所不用其極。
去找現在的那位大吧主成了唯一的路,只能期待他願意幫助我了。
12月11日
稍微展望了一下將來的計劃,在資料庫準備好之後,網站就要上線了。
靜態前端計劃使用cloudflare workers,資料庫後端也用workers。不過問題來了,workers資料持久化的方案叫kv,這是個令人血壓上升的東西。簡單地說,kv就是個python字典,然後這玩意還有容量限制,每個條目不能超過100 MB。
所以,直接塞資料庫不行,轉換成kv的格式也不行,只能另謀高就。我實在不想和伺服器打交道,workers還便宜得多,操作得當甚至一分錢都不要。
workers官方欽定了幾個第三方資料庫服務,而其中的prisma正好就支援sqlite。不過不知道prisma的費用怎麼樣,按理來說十萬出頭的行數應該只算是灑灑水。
好像prisma完全不是我理解的這個意思,我尋思還是給cloudflare交錢吧。反正無論怎樣都比自己買伺服器要便宜了,主要是還不用管運維。
嘗試用webrecorder的pywb存檔了幾頁貼吧的原始資料,warc格式。
問題相當多……首當其衝的是資料量,爬了兩三個帶圖的帖子之後,即便是gzip壓縮過的資料量也達到了115 MB。若是爬取整個貼吧,這個規模要上傳releases,恐怕是相當不利。
其次是pywb的網頁代理難以處理貼吧的一些js,有些控制元件和按鈕會失靈。
最後是我覺得最麻煩的一點,貼吧的廣告數量巨大,還時不時彈窗要求登入賬號。我平時開著廣告遮蔽外掛,對此一無所知。到時候可是無人值守執行的無頭selenium,要送個廣告遮蔽外掛進去,還要在正式爬取之前加入chinalist(針對國內廣告的遮蔽列表),談何容易。
我有點黔驢技窮。
12月12日
uncover已經完工,在經過幾輪測試後,可以視作GA(generally available,普遍可用)。
值得一提的是,貼吧後臺似乎沒有像公開貼吧那樣有著嚴格的反爬,但偶爾還是會出現timeout。
爬取公開貼吧仍然沒有什麼進展。或許現在將重心轉向前端介面或者文案會更合適?
12月13日
專案的進展速度確實放緩了。今天幾乎是原地踏步。
想起之前有一位顧問提過,自己在真實瀏覽器上用js爬了100頁也沒撞上過反爬。我詢問了一些當時操作的細節,他表示針對我的這個需求要重新測試一遍才能知分曉。
靜候他的佳音,這兩天專注公眾能看到的部分了。
12月14日
有人提議考慮放棄warc格式,但是有一位堅持要求儲存所有原始網頁到Internet Archive Wayback Machine,那麼就沒辦法放棄warc了。
Wayback Machine對百度貼吧特別不親和,例如在2016還是2017年至今Wayback Machine自行爬取到的貼吧全部是綠氣泡30x redirect,事實上沒有儲存到任何內容,諸如此類。
因此,我們自行儲存warc再借助Internet Archive認證的團隊上傳成了唯一可行的途徑。
12月16日
在幾個顧問的討論之下(由我作為溝通的橋樑),還有拉上Archive Team的IRC一塊,終於算是明確了warc格式相關的路線,那就是——
放棄warc。
具體來說,是放棄由我們親自用瀏覽器爬取和儲存warc。
過去數天,我們幾人針對百度貼吧網頁在瀏覽器和各類archiver中的行為各自做了研究和觀察,我們意識到,“在warc檔案中完美儲存所有資料”可能根本不具可行性,就算有,開發也是極為棘手的。
除了上文中已經提到的廣告問題,最大的問題是登入牆。登入牆最直觀的體現,就是在樓中樓的回覆當中。
假設一個帖子中的樓中樓有大於等於11個回覆,此時樓中樓會分出兩頁或更多,每頁最多顯示10個回覆;沒有使用者操作的情況下顯示前5條,使用者點選“展開”可以看到第一頁的全部10條。而登入牆的行為是這樣的:不登入賬號時,只能看到前5條,點選“展開”會彈出登入提示;登入賬號後則沒有任何限制,可以任意檢視。
在網頁內部邏輯上,樓中樓的元件渲染直到使用者滾動到對應的樓層才會開始,但這一過程並不依賴網路連線。實際上,在開啟帖子的一刻,會向(貼吧主站域名)/p/totalComment傳送一個xhr,返回值為當前頁中,每一個樓中樓的前10條(第一頁)內容,json格式,但並不包含第二頁及之後。樓中樓第二頁的載入是單獨的xhr,返回值是一堆html,也就是第二頁的html。
對應到我們的各種archiver和crawler中,情況大致如此:不登入賬號,樓中樓只能看頭5條;客戶端帶個油猴user script破解掉登入牆,最多可以看10條。
當然,的確可以想辦法送個登入態進去,用我的賬號或者誰的賬號也好。但這樣爬出來的內容,顯然已經很不適合上傳到wayback machine——試想一下,在wayback machine的存檔中,看到頂欄一個使用者名稱,側欄一個使用者名稱,還有這個使用者的一堆訊息通知之類,怎麼看都離譜。
更重要的是,這在技術上難度頗高。首先,我們要怎麼送登入態程序序裡?如果用wayback machine api(如果有),我甚至不確定是否可行;如果是我們自己執行的程式,比如browsertrix crawler或者手工pywb,要怎麼把一堆cookie弄到actions裡?硬編碼到程式碼裡嗎?別忘了,這部分程式是要讓actions執行的,不然沒辦法證明爬取流程可信。
這還沒完,程式操縱瀏覽器載入完網頁後,還得滾動下去,還得處理html,去挨個點選那些“展開”和“翻頁”按鈕。臥槽,光這麼一說我都感覺這複雜程度是空前的大。更何況,要實現這個功能,browsertrix crawler這種高度自動化的方案肯定不好使了,pywb+puppeteer或pywb+selenium,選一個吧……
不行了,不行了,這一覆盤才發現我們原來想做的是如何一個巨坑。
假設我們真的完成了以上的一切,會發現一個超級驚喜——投入和產出完全不成正比。
有樓中樓的帖子有多少?超過5條和需要翻頁的樓中樓有多少?這個數字絕對不會大。與實現難度相比,放棄才是更好的選擇。更何況,wayback machine自身已經可以存檔除了這些樓中樓以外的全部資料,我們的確不需要親歷親為。
我們真的無法兼顧一切且做到完美,取捨是必要的。
P.S:之前在遇到廣告那個難題時我曾考慮過,是否可以在後期人為抹掉廣告div。顯然,這個想法在我的腦中只存在了三秒不到——被人為處理過的存檔,不是原汁原味的存檔,也就失去了存檔的價值。
那麼,可不可以只存warc供我們自己用,不上傳wayback machine?這個想法只比上面那個多活了兩秒。畢竟,在有了自研™時間機器的情況下,不會有人願意重放和翻閱那一堆warc檔案的。
P.P.S:上一條研究筆記提到的綠氣泡,其實是貼吧的目錄(吧主頁)。經過測試,帖子可以正常爬取,這就足夠了。
2022年1月10日
- 上篇
有一陣子沒更新了,但其實我沒閒著,一直在擠牙膏式更新proma。
但說實話,你從我這個狀態都能看出來了。我不想寫proma。
在移動端介面的加持下,proma的開發難度已經降低了非常多,只是唯獨有一個部分,是移動端介面力所不能及的。
簡單地說,移動端介面爬出來的樓層正文,會吞掉空行。比如兩個段落間空了一行或者很多行,在移動端接口裡是看不到的,兩個段落會緊緊貼在一起,這其實也是手機app的行為。
這非常醜陋,更重要的是,有資訊的損失。而這種損失本不應該發生,因此必須想辦法修復它。
我的想法是,先用移動端介面爬樓層,入庫,再用網頁端把所有帖子爬一遍,替換所有正文為有正確空行的版本,順帶補充上簽名檔。
爬移動端的部分相當簡單,甚至可以說是一種享受(相比於處理貼吧的HTML)。資料來源是規矩的JSON,雖然存在著命名混亂和夾雜大量多餘資料之類的毛病,但瑕不掩瑜,比處理HTML舒服多了。
但畢竟最後還得和HTML打交道。說實話,這部分我是真的不願意寫,更何況也一籌莫展。過去這麼多天了,我也沒想到實現它的合理路線,其實倒不如說,我實在是太討厭百度的HTML了。
然後是一個我最近才意識到的巨大隱患——我認為吧主不太可能會把他自己的BDUSS就這樣拱手讓人。因為,我現在才意識到,BDUSS不是專門給貼吧的一個token,而是所有百度產品。
例如,百度網盤。
如果是我,打死都不可能把BDUSS給別人,更何況是給一個並不算很熟悉的網友。
然後我就想,雖然之前在Google上找不到別人公開的恢復帖子的介面,但或許可以去GitHub找找看?只要我們能找到介面,就能做出rewinder。之後,只要把成品rewinder給吧主執行就可以了,不需要讓BDUSS離開他的電腦。
還就真讓我找到了——
而接下來,我們或許迎來了整個專案立項以來,第一個好訊息。
- 下篇
這就是那個有恢復帖子介面的程式碼,這個介面我找了很長時間,本來以為必須要親自拿到大吧主的BDUSS去找,現在居然不需要了。
然而,比起接下來要發生的,找到恢復帖子介面這個寶藏,居然顯得有些平平無奇。
驚喜在這個repo的README中。
摘錄:
“以客戶端版api為基礎開發,這意味著小吧也可以封十天、拒絕申訴、解封和恢復刪帖(需要大吧主分配許可權)。”
如果他沒騙我,這意味著我不再需要找什麼大吧主的BDUSS,也不需要在整個流程無法除錯無法測試的情況下,把程式給大吧主去運行了。
我可以完成一切了。
我看到這行字的時候,真的差點要哭出來了。一個多月了,我們可曾遇到過什麼好訊息?但今天,我們終於有了一個驚喜,一個奇蹟。
當然,也有一件事讓我感到微微不快,就是我在他的程式碼中找到了透過移動端介面爬帖子目錄的方法。
遵循一個基本定理:貼吧的移動端介面總比網頁端好處理。我做了好長時間的網頁端爬帖子目錄,肯定是要廢棄的了。但必須廢棄啊,移動端介面的魯棒性比我那爬網頁的草皮架子好多了。
就是好幾天白乾了,有點不爽。
接下來要做的,就是確認一下他到底有沒有騙我,小吧到底能不能恢復刪帖了。
修訂:沒有冒犯Starry-OvO前輩的意思!只是這邊最開始是不公開的筆記,所以比較口無遮攔一點。
1月24日
很遺憾我沒能找到小吧恢復刪帖的方法,但是Tieba-Cloud-Review的作者使用者頁內留下了唯一一個聯絡方式:郵件。我嘗試透過這個郵件與作者取得聯絡,但是已經過去快兩個星期了,杳無音訊。不過有他程式碼裡介面的加持,rewinder應該能夠直接使用,到時候,把程式交給大吧主就行了。
儘管前期工作的容錯性還是低到極限了,但至少不是徹底沒有出路。
此外,透過移動端介面獲取帖子目錄的方法不可行,存在只有移動端不可見的帖子,而這類帖子的比例在前兩頁中甚至超過5%,原因不明。
雪風丟給了我一堆當年部分精品貼的本地存檔,2018年產,是那種瀏覽器裡直接按Ctrl+S儲存下來的“標題.html”加上“標題_files”的形式。其實資料量比我想象中要少。可以拿來給前期工作的幾個程式做測試,而且和我之後的路線並不衝突。
之後大概會做成torrent,和我的資料一起分發。
我花了數天編寫修復正文空行的演算法,演算法很複雜,推翻重做了好幾次,但仍然只能滿足幾個(儘管是多數)情況下的特例,魯棒性其實非常差。
意思就是,它暫且能用,但我完全不放心讓它到生產環境上去執行。
與其同時還還有新的問題:紅字和加粗。之前一直忘了這倆東西。
但是對於目前的修復演算法和程式邏輯,如何修復加粗紅字,可謂徹底走入窮途末路了。
此時有人點醒我,他大概是這麼說的:如果是他做,他會直接把網頁端的HTML原樣入庫。
我:陷入沉思
他說的確實有道理,如果直接用HTML入庫,就不再需要做任何複雜的修復。即便是有百度的垃圾資料夾在其中,也可以很容易地剔除,或是在之後我的網頁上即時修復。
這意味著,“proma”這個前期工作的資料採集部分,將立刻成熟;前期工作將立刻結束,後期的網頁與後端工作很快就能開展。
為什麼我會陷入沉思呢,因為如果這樣切換路線,將有近一半的已有程式碼要被廢棄。
但是為了獲得儘可能好的資料,割肉不可避免。
1月29日
2022-01-29 01:50:57,518 [INFO] Current page: posts, thread_id 7648701681, page 1
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_top" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_01.png);height:17px;"></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_middle" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_02.png)"><div class="post_bubble_middle_inner">加油</div></div>
2022-01-29 01:50:58,201 [CRITICAL] Unhandled element: <div class="post_bubble_bottom" style="background:url(//tb1.bdstatic.com/tb/cms/post/bubble/gaobansuinaiguo_03.png);height:118px;"></div>
elif item.get('class') == ['post_bubble_top']:
return None
# 直接放棄使用了奇怪氣泡的帖子
# 這個專案的複雜程度早已遠超我的預料,若按計劃,專案的規模絕不應該膨脹到現在這個狀況
# 隨著需要專門處理的edge case不斷增多,程式的魯棒性也肉眼可見地暴跌
# 使用了奇怪氣泡的帖子大多都是回覆,而且往往沒有複雜的格式,再加上它們的數量非常少
# 所以,對於這類帖子,直接保留原來資料庫中的content吧
1月31日
嗨,新年快樂。今天,proma已經正式GA。
這比我預期來得遲,但和專案現在的複雜程度相比,倒也算合理了。更何況正好在新年的日子,也算討個口彩了。
前期工作已接近尾聲,接下來要做的,就是檢查前期專案剩餘的bug,進行多次全量測試,確保執行的穩定性。
一切完成之後,就可以送proma和uncover去GitHub actions了。
2月5日
proma的現有程式碼已經完善,除非需要大改,應該不剩什麼要動的了。
我建立了一個私有repo用來測試actions,這玩意總是不能指望一次成功。
然而程式執行進度過半時,噩耗傳來了。actions上的程式丟擲了一個難以理解的錯誤。由於程序非正常退出,actions直接中斷了後續打包上傳的過程,弄得我非得再花一兩個小時在我自己的電腦上進行全量測試。
本地測試的環節倒是走運,成功復現了與線上環境一致的錯誤。然而,“走運”揭露出的卻是不幸:百度貼吧的rate limit(驗證碼,反爬,差不多一個意思)恢復運作了。
“恢復”是什麼意思?事情是這樣的,自除夕以來,一直到昨天,百度貼吧的反爬機制似乎被完全關閉——過去幾日的測試流程異常順利,即便是多次連續進行的全量測試,也沒有遇到過任何一次rate limit。而在此之前,百度貼吧有著堪稱野蠻的反爬機制:假設不走移動端介面,30個請求之內就會被驗證碼攔住。
這個問題倒也不算無解,爬蟲行業內的一般方法是直接掛個代理池,一個IP臭了就換下一個。對於我來說,直接把我的梯子一塊送進actions,開個負載均衡就行。proma的程式碼已經全部使用https並開啟證書驗證,即使掛代理也不會有MITM嫌疑。
只是這樣一來,工程量又要加了。
以及更惋惜的是,我們錯過了最佳的發射視窗。
另一些想說的話
這個專案已經開展整整兩個月了,看看在這兩個月裡,我為此付出了多少:
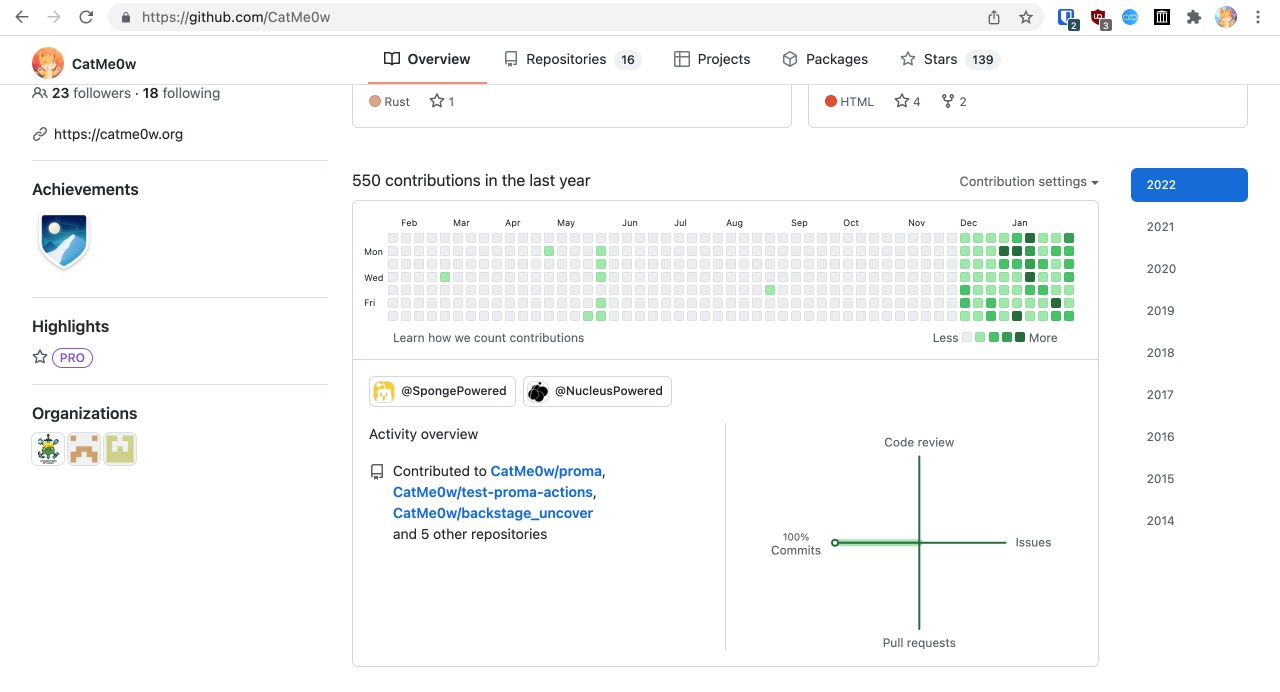
直接造就了自12月以來的全綠瓷磚。
全綠意味著,每天都有新程式碼提交。
我對這個專案懷抱著巨大的熱情,因為,我真的太想看到過去的時光了。
furry,現在也叫福瑞,在大約2018-2019年間出現了暴漲。furry社群的規模在很短的時間內變得空前的龐大,而這量變也引發了質變——furry,彷彿在一夜之間,變得人盡皆知了。現在,在b站隨便找個人,他大機率知道什麼是“福瑞”;甚至連我的小學同學都有不少已經知道furry了。
furry內部其實早已出現了一些不和諧的跡象,這些跡象正是暴漲所帶來的副作用。譬如,在furry被大眾廣泛知悉之前,內部就已出現了關於“低齡化”“掛人成風”的討論。
在專案的開發過程中,我看到了過去的人們留下的痕跡,很多很多。那時的圈子是真的小——2013年間,fursuit吧甚至不到一千人。而更重要的,討論也是真的和諧。在這個次文化剛剛進入國內的最初幾年,所有人都懷抱著希望與熱情,討論做裝的細節,或者是搬運YouTube上的影片,而絕不會有人撕逼或者掛人。
我們已經回不去了,但至少我們還能在回憶中擁有它。這些記憶的碎片不斷激勵我繼續做下去,勢必要把這個專案做完,哪怕最後只有自己願意看,我也滿足了。
……然而這還不是全部。如果只是這麼純粹的目的,我大可不必折騰actions和代理池。然而fursuit吧在2017-2018年間發生的事情,使得我必須折騰,這也正是我的另一半動機。
我給你講講我在貼吧後臺到底看到了什麼:2018年貼吧被奪權後,新上任的吧主是個我們從來沒見過的人,而他的真實身份是什麼呢?
是爆吧機器人。
他不是furry,甚至不是真人,只是眾多買來的機器人賬號中的一個。
而在別的地方開團混血狼狗的“飛翔之龍”等人,他們的賬號也曾被用於爆吧。
“機器人吧主”上任後的第一件事就是銷燬他們自己人爆吧的痕跡,同時也帶走了所有狼狗發的帖子,我們的歷史沒有了。
我真的很生氣,但是2018年他們的確把握住了輿論,我們當時也沒能奪回貼吧和歷史。
能得到今天這個機會,我勢必要向世人公開這一切。也正因此,我不能給對方留下一絲一毫輿論的突破口,於是我想到了利用不受人工干預的自動程式“GitHub actions”和開放原始碼軟體證明我專案的公正性。
code review的小夥伴問我,為啥這麼折騰呢,你這也太潔癖了。
我想,我沒有別的選擇。
(以後我可能會把這裡的文章選擇性的公開,很顯然這一段 大概 肯定 不會在公開的範圍中)
2月6日
我收回上一篇所說的“百度貼吧在過年期間放寬了反爬機制”,因為我剛剛發現,似乎我的Windows電腦在任何時間都不會遇到反爬驗證碼,但我的Mac電腦和actions都會,並且遭遇驗證碼的速度非常之快。
而我之所以得出上一篇的結論,大概是因為我在過年期間用的都是這臺Windows電腦進行開發和測試,因此完全沒看到驗證碼。
邪門,真是邪門。
所有平臺用的都是同一份程式碼跑的,甚至我的Mac和Windows電腦都是同一個IP,到底哪裡有差異。
不過所幸我在看到actions上的異常後,選擇更換到Mac進行全量測試,否則不可能復現這個問題,就真成了“病原體在實驗室環境不繁殖”了。
若是能找到這臺Windows電腦不受限制的秘密,就不需要折騰代理池了,執行速度也會更快。
等等,再讀一遍昨天那篇文章,我是怎麼說的?
“飛翔之龍”被用於爆吧
一切好像都說得通了!我突然理解了這幾個相似賬號之間的聯絡。
既然“飛翔之龍”曾用於爆吧,那麼無論是有著潛在的炸號風險,還是已經出現了來自百度的賬號限制,既然是要用來當吧主的,這個賬號背後的使用者一定不應該繼續使用這個有了“前科”的賬號。
如果我的假設成立,那麼這就可以解釋,為什麼“飛翔之龍”的賬號已經登出,而後來的fursuit與獸人吧吧主“AbramsDragon”使用了與“飛翔之龍”完全相同的頭像。根本是穢土轉生。
而“飛翔之龍”我們已經確認,他同時是“大召喚之門”、“軟毛藍龍馭風”、“軟毛的須臾”等等。馬甲名稱眾多,只列幾個常見的。
還剩一個疑點,那就是現在的“AbramsDragon”,之前的使用者名稱叫做“糊狸狐兔”,而這個賬號曾在2018年間用於開團混血狼狗。
現在,你仍然可以透過這個連結看到原始的古戰場: https://tieba.baidu.com/p/5686874465
混血狼狗在2018年對古戰場做的存檔,可以看到當時確實是“糊狸狐兔”的名字: https://www.bilibili.com/video/av23138512
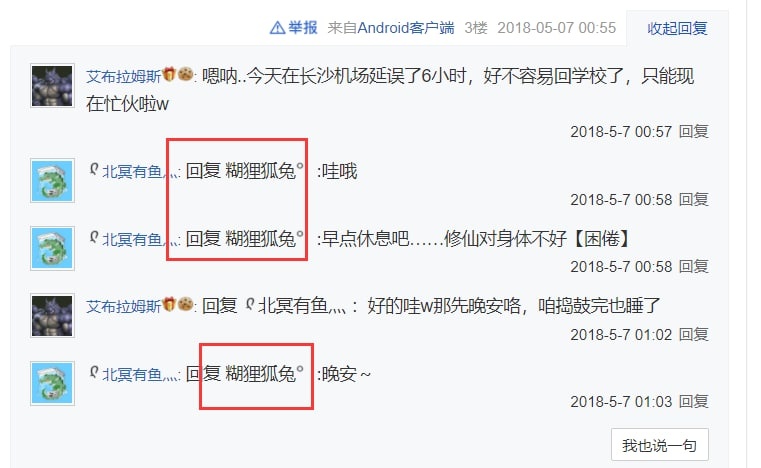
修訂:該帖已被刪除。也許是我公開這篇研究筆記之後打草驚蛇了,又或許單純只是他們又在內鬥?總之我在這裡放一個Internet Archive的存檔連結:
https://web.archive.org/web/20220328163719/https://tieba.baidu.com/p/5686874465
迴歸正題,目前我沒有任何明確證據表明“飛翔之龍”和“糊狸狐兔”背後是同一名個體(語言風格差異過大),但至少可以認定兩者關係密切。
致所有看到這行字的人:如果專案目前還沒有對外公佈,千萬不可打草驚蛇!至少只有在資料採集完畢之後才能夠對外表明此專案的存在。我會先完成資料的採集,再完成靜態主頁(入口網站主頁)。在靜態主頁完成後才算能夠公開。
儘管我最開始的期望是所有東西準備好後再發布,但是後頭的時間機器可能工期也很長,如果實在不行,提前公佈也並非不可。
2月13日
一個月過去了,我終於收到了來自Starry-OvO的回信。
他沒騙我!真的可以讓小吧主恢復帖子,而且,甚至還有“單次請求批次恢復”的介面存在,只是因為需求太小,他沒做。
要讓小吧主有恢復的能力,需要在手機上,由大吧主在吧資料中設定,而這個選項在電腦版後臺並不存在。事實上,手機和電腦的貼吧後臺儼然是兩套完整而獨立的系統,電腦版的後臺連https都根本不支援,可能自2012年之後就沒有積極維護過,也難怪之前在電腦上完全沒有找到任何與之相關的跡象。
比這更好的訊息,就是我確確實實可以親自操作了,工作的容錯性大大增加。
2月17日
事不宜遲,該開始行動了。
rewinder很可靠,一次就成功了。現在,所有能夠檢視的,曾被刪除的帖子已經全部釋放出來,我也緊接著開展了proma與uncover在本地與線上環境的測試。
proma要改的東西不少,釋放出來的帖子裡不少年代久遠,有著各種各樣奇怪的資料結構,得花一些時間專門適配。
好訊息是,第一頁帖子完全不受影響,短時間內不太可能被人發現,這意味著我的時間比預想中充足很多……當然,除了最近幾天被刪除的帖子,但願他們不會注意到這個誤差。
另外有件事讓我挺樂的。他們當年買了不少成品的爆吧服務,貼吧裡被塞進的四萬1級號就是他們的傑作。只是這些純機器人已經被百度遮蔽得差不多了,這些“外援”產生的爆吧痕跡並不是很明顯。
但是刺激的來了,這夥人還用自己的大號去接入爆吧程式,由此產生了一個奇觀:他們在fursuit吧爆吧的同時,在獸人吧倒打一耙,開團混血狼狗。而且,現在他們仍然能被觀測到的爆吧痕跡比純機器人還要多。
真的樂壞了,他們怎麼敢,怎麼敢直接拿同一個號爆吧和掛人……
在有了空前充足的資料後,我花了一些時間尋覓那些撕逼的古戰場,嘗試徹底搞清當年爆吧那夥人,也就是通常稱作的LL,他們的人員結構。
在結合Internet Archive、本地資料庫、狼狗的錄影,以及當前的貼吧狀態下,我終於徹底錘死了:艾布就是軟毛。
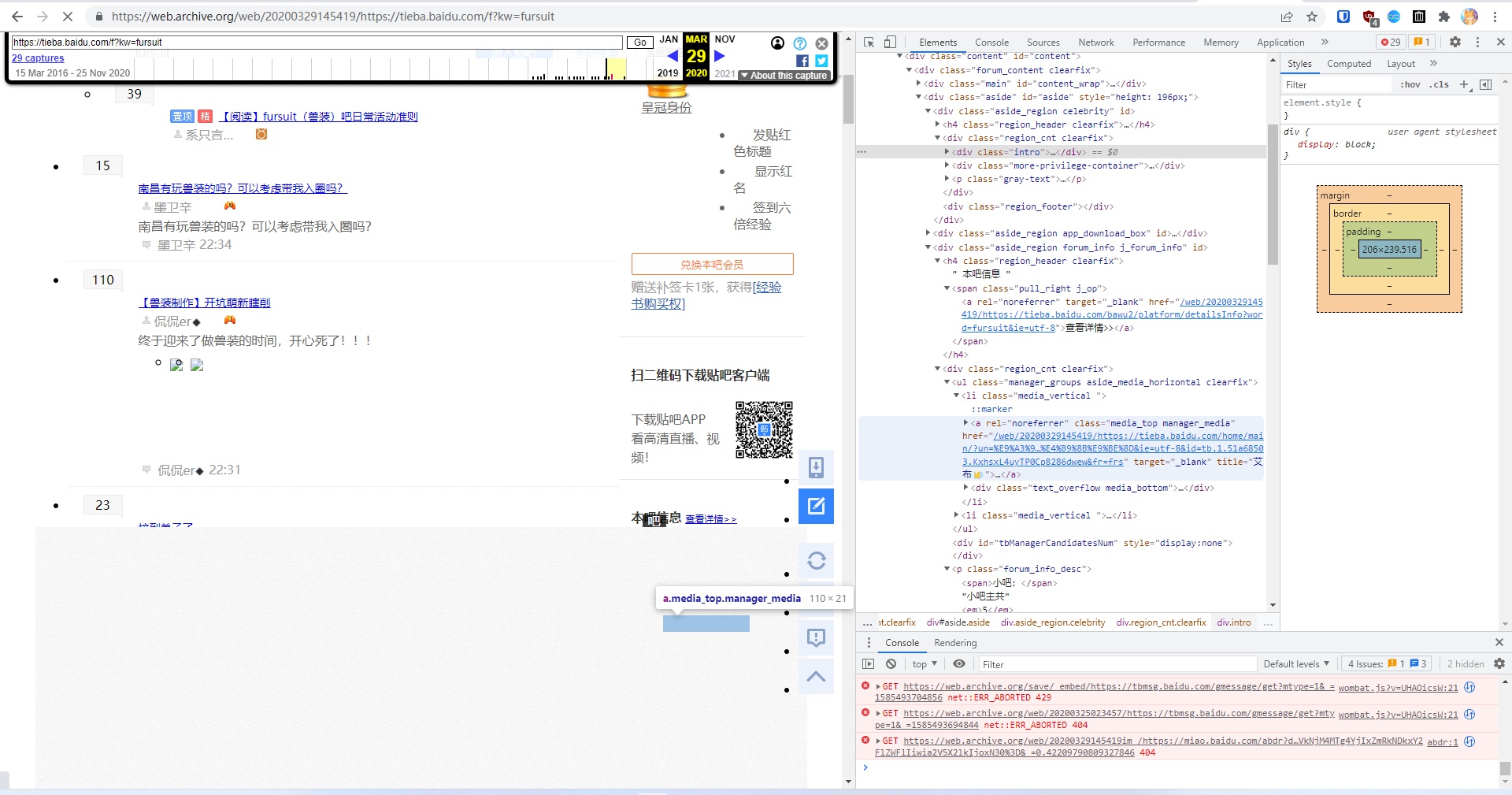
Internet Archive在2020年3月的存檔,排版有錯亂,吧主的頭像被遮擋了,但透過連結可以看到有“艾布”的名字

吧主的使用者連結,出現了“艾布”的名字,注意這個
tb.1...的部分,這是百度賬號的唯一標識之一
移除遮擋之後看到的頭像,軟毛(“飛翔之龍”)曾使用過相同的頭像
“飛翔之龍”爆吧的帖子,賬號登出後名字在公開貼吧已不可見
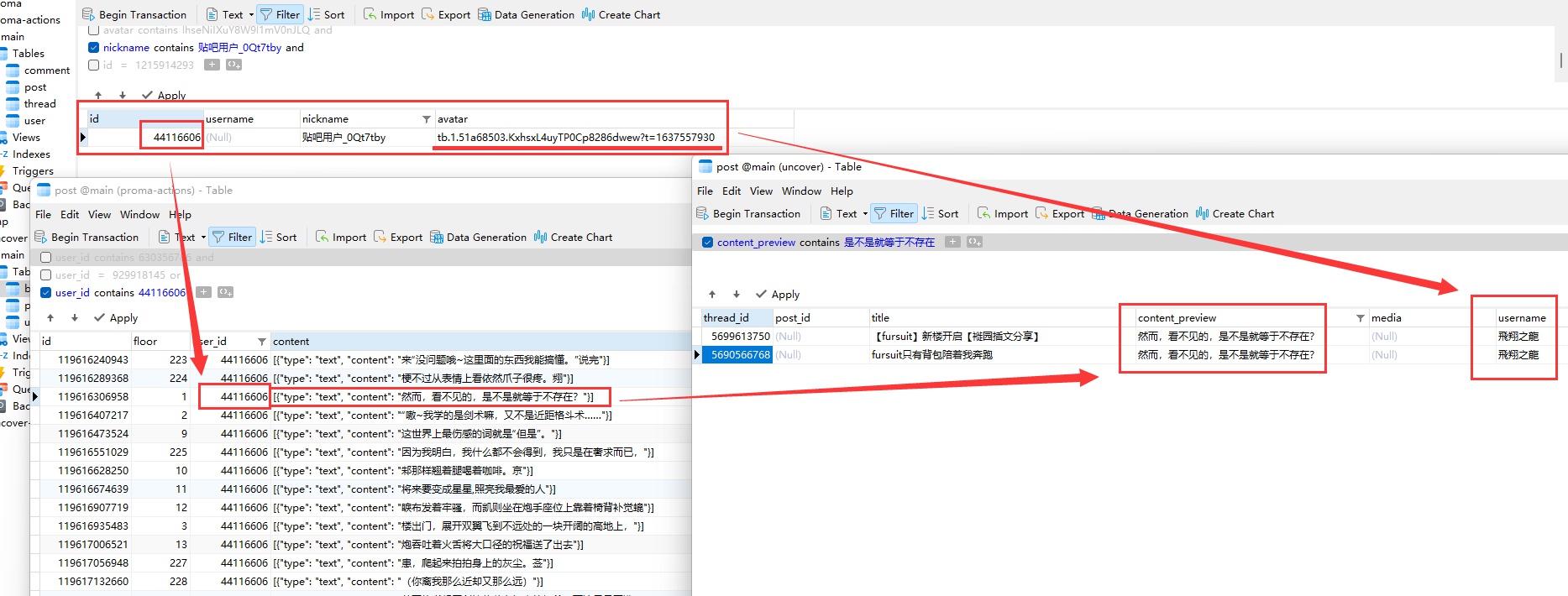
從資料庫中找到的記錄,爆吧者的使用者名稱即為“飛翔之龍”,而
tb.1...的欄位與2020年3月的吧主“艾布”相同,即相同賬號
(感謝Internet Archive送上助攻)
但是我仍然沒搞清楚“艾布拉姆斯”和“糊狸狐兔”之間的真實聯絡。
這裡是內部文件,不公開的,我就直接說了:如果要造勢,那就直接錘他們是同一個人,畢竟,下面這個是沒辦法洗的(儘管也可能就是同一個人):
顯然我不可能親自下場開團,但我們終於重新掌握了話語權,我們已經有了反攻的能力。
修訂:此處分析全錯。詳見:https://www.zhihu.com/question/327443124/answer/709795424
2月27日
中期完成了。
現在,所有暫時釋放出的帖子已經被刪回去了,貼吧恢復到與去年12月之前完全一致的狀態了。
後期主要由兩個部分構成:前端和後端,也就是我們自己設計的“貼吧模擬器”。
前端就是網頁,給終端使用者看的;後端就是和資料庫對接的伺服器部分,處理資料庫查詢結果,呈現給前端,再由前端顯示出畫面。
沒有了前期開發那麼多的不穩定因素後,終於可以在後期整點活了,比如,嘗試一下最新最潮的技術……
3月26日
我太懶了,懶得更研究筆記了。
總之,後端開發已經完成而且上線了。這意味著,後期已經完成了一半,只要完成前端,就可以正式釋出了。
後端的開發過程其實還挺艱難的,這玩意要實現的邏輯比我一開始的預想複雜許多,中途也遇到了不少困難,不過最終還是挺過來了,整出了還算能用的成品。
現在,前端開發才剛剛開始。折騰Node.js和那一大堆傻不拉嘰的打包工具和包管理器就浪費了我一整天的時間。前端開發真的是一個非常,非常,非常不健康的社群,每隔幾個月,GitHub上就會出現一批你聞所未聞的新專案,而且個個自帶兩千以上的star;每一個新專案都有著“收拾以前的所有屎山”的宏偉夢想,但它們的歸宿永遠都是成為屎山的一員,之後再被新的屎山嘗試收拾,如此往復。
不過最終對於要使用的工具和框架,我還是心中有數了,然後,就來到了前端開發的第二個難題:平面設計和文案。。。
設計和文案是如此難做,以至於即使我在前期就開了坑,到現在饢字還沒一撇,雖然中途推翻過幾次。